Eksplorasi Data Mining – Galih 13507069 –
June 17, 2009
- Abstraksi
- Definisi Data, Informasi, dan Pengetahuan
- Pengertian
- Tujuan Data mining
- Tahap-Tahap Knowledge Data Discovery (KDD)
- Keunggulan Data Mining
- Hal yang Diperlukan
- Metodologi Data Mining
- Tugas Data Mining
- Pemaparan Tugas Utama Data mining
- Masalah yang Dihadapi Saat Ini
- Kesimpulan
- Daftar Pustaka
Teknologi komputasi dan media penyimpanan telah memungkinkan manusia untuk mengumpulkan dan menyimpan data dari berbagai sumber dengan jangkauan yang amat luas. Fenomena ini terjadi dalam banyak bidang kehidupan, seperti bisnis, perbankan, pemasaran, produksi, sains, dan sebagainya.
Dalam sains misalnya, berbagai teknologi memungkinkan pengambilan data yang dilakukan secara kontinu hingga dalam jumlah bertera-tera byte. Salah satu contohnya adalah Sistem Observasi Bumi milik NASA yang mampu mengirimkan berbagai jenis data berkaitan dengan objek-objek yang diamatinya hingga berpuluh-puluh gigabyte setiap jamnya.
Dalam dunia bisnis pada era globalisasi ini para pelaku bisnis harus selalu memikirkan strategi-strategi terobosan yang dapat menjamin kelangsungan bisnis mereka. Dan tidak dapat kita pungkiri bahwa aset utama dan penting yang dimiliki oleh perusahaan masa kini adalah data-data bisnis dalam jumlah yang sangat banyak, baik data kekayaan, data pegawai, maupun data-data lain yang memuat rahasia perusahaan. Hal tersebut melahirkan kebutuhan akan adanya teknologi yang dapat memanfaatkan data-data tersebut untuk memperoleh informasi baru, yang dapat membantu dalam pengaturan strategi bisnis.
Meskipun teknologi basis data modern telah menghasilkan media penyimpanan yang ekonomis bagi aliran data yang amar besar ini, teknologi untuk membantu kita menganalisis, memahami, atau bahkan memvisualisasikannya belumlah tersedia. Hal inilah yang melatarbelakangi dikembangannya konsep Pengambilan Pengetahuan dari Basisdata (PPB) dan teknologi data mining hadir sebagai solusi.
2.1. Data
Data adalah semua fakta, atau tulisan yang dapat diproses oleh komputer. Saat ini data yang kita temui terletak dalam lingkup yang luas dan jumlah yang besar, selain itu terdiri dari format yang berbeda dan database yang berbeda pula. Termasuk juga :
– Data operasional atau transaksi, seperti penjualan, harga, inventori, payroll, dan perhitungan.
– Data nonoperasional, seperti data ramalan dan data makro ekonomi.
– Meta data mengenai data itu sendiri, seperti desain database logik atau definisi kamus data.
2.2. Informasi
Pola, asosiasi, dan hubungan di antara data ini dapat memberikan informasi. Misalnya, analisis dari data penjualan dapat memberikan informasi mengenai produk apa yang paling laku dijual.
2.3. Pengetahuan
Informasi dapat diubah menjadi pengetahuan mengenai pola yang terlihat dan trend masa depan. Dengan menganalisis pola pembelian konsumen, kita dapat mengetahui benda seperti apa yang paling disukai oleh konsumen dan kita mampu memproduksi hal yang lebih menarik sehingga dapat memperoleh keuntungan lebih.
3.1. Wikipedia
Data mining adalah proses mengekstraksi pola yang tersembunyi dari dalam kumpulan data. Karena semakin banyak data yang diperoleh, dan kira-kira jumlahnya akan menjadi 2x lipat tiap 3 tahun, data mining berubah menjadi sarana penting untuk mengolah data mentah menjadi suatu informasi.
3.2. Budi Santosa
Data Mining merupakan disiplin ilmu yang menggabungkan statistika, machine learning, database dan visualisasi. Kini sangat diperlukan baik dalam industri perbankan sampai mikrobiologi.
3.3. Veronika S. Moertini
Data mining didefinisikan sebagai satu set teknik yang digunakan secara otomatis untuk mengeksplorasi secara menyeluruh dan membawa ke permukaan relasi-relasi yang kompleks pada set data yang sangat besar. Set data yang dimaksud di sini adalah set data yang berbentuk tabulasi, seperti yang banyak diimplementasikan dalam teknologi manajemen basis data relasional. Akan tetapi, teknik-teknik data mining dapat juga diaplikasikan pada representasi data yang lain, seperti domain data spatial, berbasis text, dan multimedia (citra).
Data mining dapat juga didefinisikan sebagai “pemodelan dan penemuan pola-pola yang tersembunyi dengan memanfaatkan data dalam volume yang besar”.
3.4. Secara Umum
Data mining (kadang disebut juga data or knowledge discovery) adalah proses menganalisa data dari perspektif yang berbeda dan menyimpulkannya menjadi informasi-informasi penting yang dapat dipakai untuk meningkatkan keuntungan, memperkecil biaya pengeluaran, atau bahkan keduanya. Dengan data mining kita dapat menganalisis data dari berbagai dimensi dan sudut, mengelompokkannya, dan menyimpulkan relasi yang terbentuk. Secara teknis, data mining dapat disebut sebagai proses untuk menemukan korelasi atau pola dari ratusan atau ribuan field dari sebuah relasional database yang besar.
Dengan kemampuan Data mining (penambangan data) untuk mencari informasi bisnis yang berharga dari basis data yang sangat besar, yang dilakukan dapat dianalogikan dengan penambangan logam mulia dari lahan sumbernya, teknologi ini dipakai untuk :
a. Prediksi trend dan sifat-sifat bisnis.
Data mining mengotomatisasi proses pencarian informasi pemprediksi di dalam basis data yang besar. Pertanyaan-pertanyaan yang berkaitan dengan prediksi ini dapat cepat dijawab langsung dari data yang tersedia. Contoh dari masalah prediksi ini misalnya target pemasaran, peramalan kebangkrutan, dan bentuk-bentuk kerugian lainnya.
b. Penemuan pola- pola yang tidak diketahui sebelumnya.
Kakas data mining “menyapu” basis data, kemudian mengidentifikasi pola-pola yang sebelumnya tersembunyi dalam satu sapuan. Contoh dari penemuan pola ini adalah analisis pada data penjulan ritel untuk mengidentifikasi produk-produk, yang kelihatannya tidak berkaitan, yang seringkali dibeli secara bersamaan oleh customer.
Dibandingkan dengan Knowledge Data Discovery (KDD), istilah Data mining lebih dikenal para pelaku bisnis. Pada aplikasinya, sebenarnya Data mining bukanlah sebuah teknologi yang utuh dan mampu berdiri sendiri, Data mining merupakan bagian dari proses KDD. Sebagai komponen dalam KDD, Data mining berkaitan terutama dengan ekstraksi dan penghitungan pola-pola dari data yang ditelaah.

Gambar 1. Langkah-langkah dalam proses KDD
a. Pemahaman terhadap domain dari aplikasi, relevansinya terhadap pengetahuan yang ada dan goal dari end-user.
Dengan teknologi sekarang, tahap ini menitikberatkan pada analis / pengguna. Faktor-faktor yang dipertimbangkan :
– Apa saja bottle neck dalam domain? Apa saja proses yang berharga untuk diotomatisasi dan apa yang sebaiknya diproses secara manual?
– Apa tujuan yang diinginkan? Kriteria unjuk kerja apa saja yang penting?
b. Menciptakan himpunan data target.
Hal ini melibatkan homogenitas data, dinamika dan perubahan, strategi pengambilan sampel, tingkat kebebasan, dan sebagainya.
c. Pemrosesan pendahuluan dan pembersihan data.
Melibatkan operasi-operasi dasar seperti penghilangan derau atau “outliner”, pengumpulan informasi yang diperlukan untuk model, menentukan strategi penanganan field data yang hilang, perhitungan informasi urutan waktu, normalisasi yang sesuai, dan seterusnya.
d. Proyeksi dan pengurangan data.
Melibatkan keputusan ciri-ciri penting representasi data (bergantung pada tujuan). Penggunaan reduksi dimensionalitas atau metode-metode transformasi untuk mengurangi banyaknya variabel efektif di bawah pertimbangan atau menemukan representasi invarian bagi data, dan memproyeksikan data pada ruang-ruang yang di dalamnya sebuah solusi lebih mudah ditemukan.
e.Pemilihan tugas data mining.
Melibatkan keputusan tujuan dari proses PPB, yaitu : klasifikasi, regresi, clustering, peringkasan, pemodelan kebergantungan, atau deteksi perubahan dan deviasi
f. Pemilihan algoritma data mining untuk pencarian.
Memilih metode yang digunakan untuk menemukan pola atau mencocokkan model kedalam data. Pemilihan model dan parameter yang sesuai seringkali bersifat kritikal. Sebagai tambahan, metode datamining harus kompatibel dengan tujuan (pengguna akhir seringkali lebih tertarik pada memahami model daripada memprediksi kapabilitasnya.
g. Datamining.
Melibatkan pencarian minat dalam sebuah form atau sekumpulan representasi : pohon atau aturan klasifikasi, regresi, clustering, dan sebagainya. Pengguna dapat secara signifikan menyumbang metode datamining dengan mengikuti tahap-tahap berikutnya secara tepat
h. Penterjemahan pola-pola yang dihasilkan dari Datamining.
Pada tahap ini diputuskan apa yang menjadi pengetahuan, hal tersebut merupakan sebuah tugas yang sulit. Pencapaian hasil yang dapat diterima dapat melibatkan penggunaan beberapa pilihan berikut (mungkin juga kombinasinya) :
– Mendefinisikan sebuah skema terotomasi menggunakan ukuran “ketertarikan” dan lain-lain untuk menyaring pengetahuan dari keluaran-keluaran yang lain. Pengukuran dapat bersifat statistikal, goodness of fit, atau kesederhanaan dibandingkan dengan yang lain.
– Menyandarkan pada teknik visualisasi untuk membantu analis memutuskan utilitas pengetahuan yang terekstraksi atau mencapai kesimpulan tentang data / fenomena underlying.
– Menyandarkan secara keseluruhan kepada pengguna untuk bergeser melalui pola-pola yang diturunkan dengan harapan of coming across items of interest.
Tahap ini mungkin menghasilkah perubahan-perubahan pada tahap-tahap selanjutnya, atau pengulangan seluruh proses.
i. Konsolidasi pengetahuan yang ditemukan.
Hal ini juga melibatkan pengecekan dan pemecahan konflik-konflik yang potensial dengan pengetahuan atau keyakinan sebelumnya
Ketika teknologi informasi dalam skala besar terpisah menjadi transaksi dan sistem analisis, data mining menjadi penghubung di antara keduanya. Empat jenis keterhubungan yang dapat diciptakannya adalah :
– Classes: Data yang disimpan dikelompokkan dalam group yang dapat diprediksi.
– Clusters: Data yang dikelompokkan, diklasifikasikan berdasarkan relasi logik atau kesukaan konsumen.
– Associations: Identifikasi data agar kita dapat mengetahui hubungan antar data.
– Sequential patterns: Pengolahan data untuk memprediksikan pola tingkah laku dan trends konsumen terkini.
Data mining terdiri dari 5 konsep penting :
– Ekstrak, mengubah, dan memuat data transaksi ke dalam sistem data warehouse.
– Menyimpan dan mengatur data dalam sebuah sistem database multidimensional.
– Menyediakan akses data pada analis bisnis dan professional IT.
– Menganalisis data dengan aplikasi software.
– Memberikan data dalam bentuk yang mudah ditelaah, seperti grafik atau tabel.
Level-level analisis yang ada :
– Artificial neural networks: Model prediksi non-linear yang dipelajari berdasarkan konsep sistem saraf manusia.
– Genetic algorithms: Teknik optimasi yang menggunakan proses yang disadur dari kombinasi genetika, mutasi, dan seleksi alam yang sesuai dengan konsep evolusi.
– Decision trees: Struktur bentuk pohon yang merepresentasikan pilihan dan akibat yang dipilih karenanya.
– Nearest neighbor method: Sebuah teknik yang mengelompokkan tiap record dalam dataset menurut kombinasi dari klas yang memuat k record yang hampir mirip dengan dataset yang tercatat.
– Rule induction: Hasil pengolahan dari aturan if-then dari database pada signifikan statistikal.
– Data visualization: Interpretasi visual dari relasi kompleks dalam data multidimensional.
Secara teknis ada tiga hal yang diperlukan dalam data mining:
a.Data
Harus ada data mentah sebagai bahan untuk diolah.
b.Modelling.
Bagaimana model yang kita pilih untuk menyelesaikan problem yang kita hadapi. Apakah dengan klastering, klasifikasi atau prediksi (akan dijelaskan kemudian).
c.Teknik data mining
Setelah itu harus ada teknik data mining yang kita kuasai untuk menyelesaikan model yang kita punyai.
Data mining yang ada pada proses KDD seringkali merupakan penerapan dari metodologi data mining yang sudah ada. Di sini kita perlu mengenal apa itu Pola dan Model, Pola dapat diartikan sebagai instansiasi dari Model. Sebagai contoh f(x) = 2×2 + 5x + 3 adalah pola terapan dari model f(x) = ax2 + bx + c. Data mining mencari model apa yang cocok ke data yang diteliti, atau pola dari data tersebut. Ada dua pendekatan matematis yang digunakan dalam pencocokan model : statistik yang memberikan efek non-deterministik dan logik yang murni deterministik. Namun pendekatan statistik lebih sering dipakai karena lebih sesuai dengan ketidakpastian yang ada pada pola data-data di dunia riil.

Gambar 2.
Empat Jenis Inti Tugas Data Mining
Inti dari Tugas Data mining tersebut adalah :
a. Predictive Modelling
Predictive Modelling digunakan untuk membangun sebuah model untuk target variable sebagai fungsi dari explanatory variable. Explanatory variable dalam hal ini merupakan semua atribut yang digunakan untuk melakukan prediksi, sedangkan target variable merupakan atribut yang akan diprediksi nilainya. Predictive modeling task dibagi menjadi dua tipe yaitu : Classification digunakan untuk memprediksi nilai dari target variable yang discrete (diskret) dan Regression digunakan untuk memprediksi nilai dari target variable yang continu (berkelanjutan).
b. Association Analysis
Association analysis digunakan untuk menemukan aturan asosiasi yang memperlihatkan hubungan antara nilai atribut yang sering muncul secara bersamaan dalam satu himpunan data.
c. Cluster Analysis
Tidak seperti klasifikasi yang menganalisa kelas data obyek yang mengandung label. Clustering menganalisa objek data tanpa memeriksa kelas label yang diketahui. Label-label kelas dilibatkan di dalam data training. Karena belum diketahui sebelumnya. Clustering merupakan proses pengelompokkan sekumpulan objek yang sangat mirip.
d. Anomaly Detection
Anomaly Detection merupakan metode pendeteksian suatu data dimana tujuannya adalah menemukan objek yang berbeda dari sebagian besar objek lain. Anomaly dapat di deteksi dengan menggunakan uji statistik yang menerapkan model distribusi atau probabilitas untuk data.
Data Mining
Prediksi menggunakan beberapa variabel atau field-field basis data untuk memprediksi nilai-nilai variabel masa mendatang yang diperlukan, yang belum diketahui saat ini. Deskripsi berfokus pada penemuan pola-pola tersembunyi dari data yang ditelaah. Dalam konteks KDD, deskripsi dipandang lebih penting daripada prediksi. Prediksi dan deskripsi pada data mining task akan dijelaskan di bawah ini.
a. Klasifikasi adalah fungsi pembelajaran yang memetakan (mengklasifikasi) sebuah unsur (item) data ke dalam salah satu dari beberapa kelas yang sudah didefinisikan. Gambar 2 menunjukkan pembagian sederhana pada data peminjaman menjadi dua ruang kelas (punya dan tidak punya peminjaman). Pada gambar tersebut, x merepresentasikan peminjaman yang bermasalah, dan o peminjaman yang pengembaliannya lancar.

Gambar 3.
Batas klasifikasi linier sederhana pada himpunan data peminjaman.
b. Regresi adalah fungsi pembelajaran yang memetakan sebuah unsur data ke sebuah variabel prediksi bernilai nyata. Aplikasi dari regresi ini misalnya pada prediksi volume biomasa di hutan dengan didasari pada pengukuran gelombang mikro penginderaan jarak jauh (remotely-sensed), prediksi kebutuhan kustomer terhadap sebuah produk baru sebagai fungsi dari pembiayaan advertensi, dll. Gambar 3 menunjukkan regresi linear sederhana dimana “total peminjaman” (total debt) diplot sebagai fungsi linier dari penghasilan (income): pengeplotan ini menghasilkan kesalahan besar karena hanya ada korelasi sedikit antara kedua variabel ini.

Gambar 4.
Regresi linier sederhana untuk himpunan data peminjaman.
c. Pengelompokan (clustering) merupakan tugas deskripsi yang banyak digunakan dalam mengidentifikasi sebuah himpunan terbatas pada kategori atau cluster untuk mendeskripsikan data yang ditelaah. Kategori-kategori ini dapat bersifat eksklusif dan ekshaustif mutual, atau mengandung representasi yang lebih kaya seperti kategori yang hirarkis atau saling menumpu (overlapping). Gambar 4 menunjukkan pembagian himpunan data peminjaman menjadi 3 cluster. Di sini, cluster – cluster dapat saling menumpu, sehingga titik-titik data dapat menjadi anggota lebih dari satu cluster. (Label x dan o pada gambar sebelumnya diubah menjadi + untuk mengindikasikan bahwa keanggotaan kelas diasumsikan belum diketahui.).

Gambar 5.
Pengelompokan himpunan data peminjaman menjadi 3 cluster
d. Peringkasan melibatkan metodologi untuk menemukan deskripsi yang ringkas dari sebuah himpunan data. Satu contoh yang sederhana adalah mentabulasikan mean dan deviasi standar untuk semua field-field tabel.
e. Pemodelan Kebergantungan adalah penemuan sebuah model yang mendeskripsikan kebergantungan yang signifikan antara variabel-variabel. Model kebergantungan ini ada di 2 tingkat : tingkat struktural yang menspesifikasikan variabel-variabel yang secara lokal bergantung satu sama lain, dan tingkat kuantitatif yang menspesifikasikan tingkat kebergantungan dengan menggunakan skala numerik
f. Prediksi Model yaitu pola-pola yang dianalisis dari database, diolah lebih lanjut untuk memprediksi keadaan masa mendatang. Pemodelan Prediksi memungkinkan user untuk mengirimkan record dengan beberapa field kosong, dan sistem akan menebak nilai yang kosong tersebut dengan pola-pola sebelumnya yang ditemukan dari basis data.
g. Analisis Forensik bertujuan menemukan keanehan atau elemen data yang tidak biasa. Untuk mencari data yang tidak biasa pertama kali yang dicari adalah normal dari data tersebut, kemudian mendeteksi item-item deviasi dari dari data yang biasa dengan batasan yang diberikan.
Masalah-masalah yang dihadapi dalam mengaplikasikan Knowledge Data Discovery kini pun makin kompleks, sehingga KDD harus dikembangkan untuk dapat mengatasi masalah-masalah tersebut, seperti :
– Kesalahan input data dan missing data pada basisdata.
– Dinamisnya data dan pengetahuan sehingga harus diimbangi penemuan pola-pola baru.
– Besarnya ukuran basisdata, dengan jutaan record dan berukuran giga.
– Dimensi permasalahan yang luas, selain jutaan record tetapi juga jumlah field (atribut, variabel) yang besar.
– Relasi antar-field basisdata yang makin kompleks. Saat ini data mining masih dirancang untuk relasi yang cukup sederhana.
– Sistem KDD susah berintegrasi dengan sistem luar karena didesain untuk dapat berdiri sendiri. Integrasi yang dimaksud bisa terjadi dengan DBMS, kakas-kakas spreadsheet dan visualisasi, serta pencatat sensor waktu-nyata.
Teknologi Data mining dapat menganalisis, memahami, atau memvisualisasikan record dalam basis data, sehingga user dapat memahami suatu pola yang terbentuk dengan lebih mudah. Data mining juga telah membantu para pelaku bisnis untuk mempertahankan dan mengembangkan bisnis mereka.

Akan tetapi, teknologi ini masih bersifat standalone sehingga susah berdampingan dengan bidang lain di dunia teknologi. Oleh sebab itu, inovasi-inovasi baru mengenai KDD dan Data Mining masih terus diperlukan untuk dapat mengatasi hal tersebut dan masalah-masalah lain yang ada.
Cerita Tambahan
 Selain masalah di atas, terdapat pula cerita menarik tentang data mining. Di banyak toko di Amerika, rak tempat popok diletakkan berseberangan dengan rak penjualan bir. Mengapa demikian? Hal ini berkaitan dengan hasil analisis yang dilakukan dengan data mining. Menurut penelitian pada hasil pembelian konsumen, kaum pria di Amerika yang sudah menikah biasanya akan membeli bir dan popok di saat yang bersamaan, karena istri mereka kebanyakan merupakan bisnis women, sehingga para suami membeli bir agar dapat beristirahat dengan tenang plus popok agar bayi mereka tidak rewel. That’s the Data Mining used for! ^^
Selain masalah di atas, terdapat pula cerita menarik tentang data mining. Di banyak toko di Amerika, rak tempat popok diletakkan berseberangan dengan rak penjualan bir. Mengapa demikian? Hal ini berkaitan dengan hasil analisis yang dilakukan dengan data mining. Menurut penelitian pada hasil pembelian konsumen, kaum pria di Amerika yang sudah menikah biasanya akan membeli bir dan popok di saat yang bersamaan, karena istri mereka kebanyakan merupakan bisnis women, sehingga para suami membeli bir agar dapat beristirahat dengan tenang plus popok agar bayi mereka tidak rewel. That’s the Data Mining used for! ^^
Budi santosa’s site » Data Mining. Tanggal akses : 6 Juni 2009 pk. 18.27
Dwiyanto, Arif Rifai.1997.Makalah “Data Mining“.
Electronic Textbook Statsoft.1984.Statsof.Inc
En.wikipedia.org/wiki/Data_mining. Tanggal akses : 6 Juni 2009 pk. 17.55
Ilmukomputer.org/category/datamining. Tanggal akses : 6 Juni pk. 18.13
Michalski R.S., Bratko I., Kubat M. “Machine Learning and Data Mining, Methods and Applications”.1999. John Wiley & Sons Ltd., New York.
Moertini, Veronica. Data Mining Sebagai Solusi Bisnis. 2002.
Moxon B, “Defining Data Mining”.DBMS Online. 1996.
http://www.dbmsmag.com/9608d53.html
Prasetyo, Philips Kokoh. 2006. “Data Mining Task“. Tanggal akses : 6 Juni 2009 pk. 18.44

Eksplorasi: Object Oriented Database
June 11, 2009
by Elvina (13507082)
Sebelumnya, ingin review sedikit tentang Object Oriented.
Objek merupakan pemodelan sistem yang lebih natural dan di dalam dunia nyata, objek bisa dilihat di mana saja. Konsep objek ini diturunkan menjadi kelas, yaitu blue-print dari objek itu sendiri.
Object oriented tidak bisa dipisahkan dari konsep:
1. Encapsulation (pemaketan data berserta metode)
2. Inheritance (penciptaan kelas baru dengan mewarisi karakteristik yang telah ada ditambah karakteristik unik kelas baru)
3. Polymorphism (satu nama kelas yang dapat menyatakan objek yang berbeda-beda).
Apa sih OODB itu??
Object-oriented database atau object database adalah sebuah model basis data yang informasinya direpresentasikan dalam bentuk objek, seperti yang digunakan pada pemograman berorientasi objek. OODB direkomendasikan ketika ada kebutuhan bisnis untuk memproses data yang kompleks.Sesuai dengan namanya, OODB adalah gabungan kemampuan basis data yang dikombinasikan dengan bahasa pemograman berorientasi objek. Lebih lanjut, OODB ini tidak hanya menjadi jenis baru dari basis data, tapi juga menghasilkan sistem manajemen basis data (SBD) yang dinamakan Object Database Management System (ODBMS).Kemampuan yang dimiliki oleh bahasa pemograman berorientasi objek antara lain: tipe data abstrak, inheritance (pewarisan), dan identitas objek. Jika dikombinasikan dengan basis data, akan menjadi OODB yang: persisten, mendukung adanya transaksi, query yang simple untuk data yang besar, akses dan control yang konkuren, keamanan, dan data recovery.Beberapa basis data berorientasi objek didesain agar bisa bekerja dengan baik dengan bahasa pemograman tertentu seperti Phyton, Perl, Java, C#, Visual Basic .NET, Objective-C, dan Smalltalk.
Sejarah OODB..
Istilah OODB pertama kali muncul pada tahun 1985. Proyek-proyek yang terkenal dari perkembangan OODB ini antara lain:- Encore-Ob/Server (Brown University)
– EXODUS (University of Wisconsin-Madison)
– IRIS (HP)
– ODE (Bell Labs)
– ORION (Microelectronic and Computer Technology Corporation)
– dll.Produk komersial awal yang memakai konsep OODB ini adalah Gemstone, Gbase, dan Vbase. Pada awal sampai pertengahan tahun 1990-an, berkembang produk komersial lain dan produk-produk baru lainnya terus berkembang menggunakan OODB ini.Untuk ODBMS sendiri, konsep yang ditekankan adalah persistensi yang dimiliki oleh bahasa pemograman objek. Produk komersial awalnya diintegrasikan dengan bahasa yang bermacam-macam seperti GemStone memakai bahasa Smalltalk, Gbase yang menggunakan LISP, Vbase menggunakan COP, dan lain sebagainya. Di tahun 1990-am, C++, Java, dan C# mendominasi pasaran ODBMS.
Mulai tahun 2004, OODB bisa berkembang dengan sangat pesat ketika ada sistem open source OODB muncul dan secara umum mudah untuk digunakan.
Kenapa OODB??
Dilihat dari sisi industry, OODB memberikan pelayanan integrasi data dan data sharing. OODB adalah kombinasi terintegrasi yang baik dari operating sistem, basis data, bahasa pemograman, spreadsheets, word-processor, dan expert system intelegensia buatan.
OODB memungkinkan Referential Sharing, yaitu aplikasi, produk,atau objek yang berbagai macam yang bisa dibagi menjadi sub-object. Referential sharing inilah yang mendukung diterapkannya identitas objek dan pewarisan.
==================================================
Part 2 of Object Oriented Database (OODB) Exploration
25 Juni 2009
Struktur Object di OODB
Paradigma OODB didasarkan pada enkapsulasi data dan kode. Seperti yang telah diketahui, enkapsulasi menyebabkan isi dari sebuah objek tidak terlihat di dunia luar objek tersebut. Secara konsep, semua interaksi antara objek dan sistem di luar dirinya dilakukan via messages. Interface antara objek dan sistem di luar dirinya inilah yang dinamakan kumpulan dari pesan (set of messages).
Secara umum, sebuah objek berasosiasi dengan
1. Sebuah himpunan variable (a set of variables) yang mengandung data untuk objek dan variable yang berkorespondensi dengan atribut di model E-R.
2. Sebuah himpunan pesan (a set of variables); kesinilah objek member respon. Tiap pesan bisa mempunyai 0, 1 atau banyak parameter.
3. Sebuah himpunan method (a set of variables) ; masing-masingnya adalah badan kode untuk mengimplementasikan pesan. Method mengembalikan nilai sebagai respon pesan.
Diilustrasikan dengan mengambil contoh entitas employee dalam basis data bank. Misalnya gaji tahunan karyawan dihitung dengan cara yang berbeda untuk tiap karyawan. Manajer mendapatkan bonus sesuai dengan performa bank, sedangkan teller mendapat bonus berdasarkan jumlah jam mereka bekerja. Dalam kasus ini, semua objek employee berhubungan dengan message gaji-tahunan, tapi mereka dihitung dengan cara yang berbeda. Dengan mengenkapsulasi informasi bagaimana mendapatkan gaji tahunan karyawan dalam objek employee, semua objek employee bisa menampilkan interface yang sama. Karena hanya interface external yang ditampilkan oleh sebuah objek adalah a set of message yang berhubungan dengan objek tersebut, maka dimungkinkan untuk memodifikasi definisi method dan variable tanpa mempengaruhi sisa sistem lain.
Dalam OODB, kita mengekspresikan atribut turunan dari entitas model E-R sebagai read-only message. Read-only message tidak mempengaruhi nilai dari variable dalam objek. Setiap atribut pada entitas HARUS mempunyai variable dan pasangan messages dari objek yang berhubungan dalam model OO. Misalnya atribut address dari entitas employee bisa direpresentasikan dengan:
- Variable address
- Message get-address
- Message set-address (dengan parameter new-address untuk mengupdate address).
Object Classes dalam OODB
Biasanya, ada banyak objek yang sama dalam basis data. Sama di sini maksudnya mereka merespon message yang sama, menggunakan method yang sama, dan mempunyai variable untuk nama dan tipe yang sama. Akan sangat sia-sia jika kita harus mendefinisikan masing-masing objek secara terpisah. Oleh karena itu, kita menggabungkan objek-objek yang sama ini dalam sebuah class (kelas). Masing-masing objek adalah instansiasi dari kelasnya.
==================================================
Part 3 of Object Oriented Database (OODB) Exploration
10 Juli 2009
Inheritance (Pewarisan)
Sebuah skema OODB biasanya membutuhkan banyak kelas. Namun, kebanyakan dari kelas-kelas ituserupa. Misalnya, OO untuk aplikasi bank, customer dan employee bank bisa dikatakan serupa karena mempunyai atribut/variable yang sama, seperti nama, alamat, dll. Namun, tentu saja tidak semuanya sama dan ada variable spesifik yang hanya dimiliki oleh customer atau employee saja. Objek yang mempunyai beberapa variable yang sama ini bisa didefinisikan dalam sebuah representasi jika kita menggabungkannya dalam satu kelas. Representasi langsungnya bisa dengan menyediakan tempat untuk kelas dalam sebuah spesialisasi hierarki (“ISA” relationship). Kita bisa mengatakan bahwa employee adalah sebuah spesialisasi dari person dan customer juga spesialisasi dari person, karena sama-sama memiliki atribut yang dimiliki oleh person.
Konsep dari hierarki kelas serupa dengan konsep dari hierarki spesialisasi yang kita kenal dalam model ER. Variable dan method yang dimiliki oleh employee dan customer bisa diasosiasikan dengn kelas person. Spesialisasi kelas ini dikenal juga dengan subclass. Maka employee adalah subclass dari person, customer juga subclass dari person.
") Dalam banyak kasus, bisa terjadi multiple inheritance, yang mengizinkan sebuah kelas untuk menurunkan variable dan method dari multiple superclasses. Hubungan kelas-subkelas direpresentasikan dengan adanya directed acyclic graph (DAG) di mana setiap kelas bisa memiliki lebih dari satu superclass.
Dalam banyak kasus, bisa terjadi multiple inheritance, yang mengizinkan sebuah kelas untuk menurunkan variable dan method dari multiple superclasses. Hubungan kelas-subkelas direpresentasikan dengan adanya directed acyclic graph (DAG) di mana setiap kelas bisa memiliki lebih dari satu superclass.
Contoh kasus multiple inheritance ini adalah basis data sebuah universitas. Dalam sebuah universitas, person bisa menjadi student ataupun teacher. Jadi di basis data universitas ada kelas student dan ada kelas teacher, yang merupakan subclass dari person. Tapi terdapat juga kasus di mana ada student yang juga bekerja sebagai teacher-assistant, yang mana kelas teacher-assistant ini adalah subkelas dari kelas student dan kelas teacher.
Pada kasus-kasus tertentu terjadi ambiguitas jika ada variable yang sama, misalnya student mempunyai departemen tertentu, begitu juga dengan teacher. Ambiguitas akan terjadi pada teacher-assistant, di mana sebagai student dia memiliki departemen dan sebagai teacher juga begitu. Namun, hal ini bisa diakali dengan memberi nama berbeda untuk departemen tiap kelas (jangan hanya menggunakan kata ‘dept’, tapi pakai ‘student-dept‘ dan ‘teacher-dept’), atau membuat treat error untuk kasus seperti ini, atau jika susah, user terpaksa membuat kelas baru, yaitu kelas teacher-assistant. Tapi diingatkan lagi, kasus ambiguitas ini tidak selalu terjadi.
Contoh multiple inheritance:
")


Object Identity (Identitas Objek)
Sebuah objek akan menyimpan identitasnya walaupun ada beberapa atau semua nilai dari variablenya berubah-ubah atau method-nya didefinisikan ulang. Sistem OO biasanya menggunakan sebuah object-identifier untuk mengidentifikasi objek. Objek identifier harus unik, yang artinya tidak ada 2 objek yang memiliki identifier yang sama. Sebaiknya, user langsung membuat identifier yang unik untuk setiap objek dan tidak menggunakan system-generated identifier karena identifier yang dibuat akan bergantung pada sistem dan bisa menjadi redundan.
Identitas objek bisa berupa nilai (value), misalnya primary key objek yang mengidentifikasi objek tertentu; atau bisa menggunakan nama (biasanya dipakai pada sistem file, satu file dengan file lain dibedakan dari namanya).
Object Containment
Terkadang, ada objek yang mengandung objek lain. Objek ini disebut complex object atau composite object. Misalnya, pada sebuah sepeda. Sepeda adalah satu objek, yang memiliki roda. Roda adalah objek baru, namun dimiliki oleh sepeda. Roda sendiri juga memiliki ban, jeruji/velg. Makanya, containment ini juga bisa memiliki banyak level, yang menciptakan hierarki containment antar objek. Hubungan antar kelas dalam containment ini adalah is-part-of, bukan is-a. Hubungan antar kelas digambarkan dalam skema dengan menggunakan DAG juga.
Dengan adanya containment, user yang berbeda bisa melihat data-data tertentu sesuai dengan kebutuhannya. Misalnya seorang wheel-designer bisa fokus pada kelas roda, tanpa terlalu memperhatikan objek lain yang juga merupakan komponen penyusun sepeda seperti rem, dll.
==================================================
Part 4 of Object Oriented Database (OODB) Exploration
24Juli 2009
Nah, pada part sebelumnya, yaitu part 2 dan 3, sudah dijelaskan mengenai konsep dasar OO dalam level yang masih abstrak. Untuk menggunakan konsep dasar itu, kita harus mengekspresikannya dalam sebuah bahasa pemrograman OO. Kita bisa melakukannya dalam 2 cara:
1. Menggunakan konsep OO murni sebagai design tool dan menuliskan kodenya, misalnya basis data relasional. Kita menggunakan pendekatan ini ketika kita menggunakan entity-relationship diagram ke model data, lalu secara manual mengubah diagramnya menjadi kumpulan relasi.
2. Kita mengkombinasikan konsep OO dalam sebuah bahasa yang kita lakukan untuk memanipulasi data. Dengan pendekatan seperti ini, ada beberapa bahasa yang bisa diintegrasikan. Misalnya dengan menggunakan SQL yang ditambah dengan tipe kompleks dan OO.
Tapi, bisa juga dengan menggunakan bahasa pemrograman yang sudah ada dan memperluas cakupannya dengan basis data. Nah, bahasa seperti inilah yang disebut persistent programming languages.
Kita akan membahas lebih lanjut mengenai persisten programming languages ini.
Persistent Programming Languages
Bahasa basis data berbeda dengan bahasa pemograman tradisional karena bahasa basis data secara langsung memanipulasi data secara persistent, yaitu data yang terus ada bahkan ketika program yang dibuat telah dihentikan.
Untuk mengakses basis data hanyalah salah satu komponen dati aplikasi nyatanya (real world application). SQL memang efektif untuk memanipulasi data, tapi bahasa pemogramanlah yang dibutuhkan untuk mengimplementasikan komponen lain dari aplikasi, seperti user interface atau keterhubungan dengan komputer lain.
Persistent programming language adalah bahasa pemrograman yang diperluas dengan konsep yang meng-handle data yang persistent.
Untuk persistent programming language, untuk eksplorasi kali ini, saya akan memakai contoh bahasa C++.
Persistent C++ Systems
C++ menyediakan features yang bisa mendukung persistansi data tanpa mengubah bahasa itu sendiri. Misalnya, kita mendeklarasikan sebuah kelas yang disebut Persisten_Object dengan atribut dan method untuk mendukung persistensi ini; kelas lain juga harus persisten sehingga bisa dibuat subclassnya ataupun pewarisannya juga persisten.
Bahasa C++ juga mengizinkan kita untuk kembali mendefinisikan sendiri nama dan operator fungsi-fungsi standar, seperti +, -, pointer referens (->), dan lain lain. Kemampuan ini disebut overloading.
C++ menyediakan kemampuan agar data bisa persisten dengan class library mempunyai keuntungan kita bisa membuat perubahan yang kecil sehingga gampang untuk diimplementasikan.
ODMG C++
Standardisasi dari perluasan bahasa C++ ini agar bisa persisten dilakukan oleh Object Database Management Group (ODMG) di mana tahun 1993 mengeluarkan versi pertama dan tahun 1997 mengeluarkan versi kedua (ODMG 2.0). Untuk tugas eksplorasi ini, karena banyak mendapatkan referensi dari ODMG 2.0, versi ini akan digunakan sebagai bahan contoh.
Ekstensi dari ODMG C++ ini dibagi menjadi 2 bagian:
(1) C++ Object Definition Language (C++ ODL)
(2) C++ Object Manipulation Language (C++ OML)
C++ ODL
C++ ODL memperluas sintaks definsi tipe C++.
Contoh kode yang ditulis dalam C++ ODL:
class Branch: public d_Object{
public:
d_String branch_name;
d_String address;
d_Long assets;
};
class Account: public d_Object{
private:
d_Long balance;
public:
d_Long account_number;
d_Set<d_Ref<Customer>> owners;
d_Long find_balance();
int unpdate_balance(d_Long delta);
};
class Person: public d_Object{
public:
d_String name;
d_String address;
};
class Customer: public Person{
public:
d_Date member_from;
d_Long customer_ID;
d_Ref<Branch> home_branch;
d_Set<d_Ref<Account>>accounts;
};
Dalam contoh di atas, skema terdiri dari 4 kelas. Masing-masing kelas adalah subclass dari d_Object. Kelas Branch, Account, Person adalah subclass langsung dari d_Object, kelas Customer subclass dari Person, sedangkan Person subclass dari d_Object, jadi secara tidak langsung Customer juga subclass dari d_Object. Tipe d_String, d_Long, d_Date adalah tipe standar yang didefinisikan ODMG 2.0.
Kelas d_Ref<> dan d_Set<> adalah kelas template yang sudah didefinisikan juga oleh ODMG 2.0.
Pada contoh, d_Ref<Branch> digunakan di kelas Customer sebagai referens atau persistent pointer. Tipe d_Set<d_Ref<Customer>> yang digunakan di kelas Account adalah kumpulan pointer ke objek Account.
C++ OML
Contoh:
int create_account_owner(String name, String address){
d_Database bank_db_obj;
d_Database *bank_db =& bank_db_obj;
bank_db->open(“Bank-DB”);
d_Transaction Trans;
Trans.begin();
d_Ref<Account> account = new(bank_db,”Account”) Account;
d_Ref<Customer> cust = new(bank_db,”Customer”) Customer;
cust->name=name;
cust->address=address;
cust->accounts.insert_element(account);
account->owners.insert_element(cust);
//kode lain untuk cust_id, acc_num, dll
Trans.commit();
bank_db->close();
}
Awalnya, program membuka basis data untuk memulai transaksi. Lalu program membuat objek account dan pemilik baru menggunakan operator new. Pada OML ini, kelas d_Object punya operator new yang akan mengalokasikan memori untuk menyimpan data baru.
Kelas template d_Set<> memiliki method yang digunakan untuk menyisipkan customer dan account dalam kumpulan yang tepat setelah objek customer dan account dibuat.
Di akhir program menjalankan transaksi dan akhirnya keluar dari basis data.
Object-oriented Database Query
Pertama, kita akan membahas tentang Object Query Language (OQL).
Dalam OODBS, query-qurey diekspresikan seperti notasi SQL, yang disebut OQL. OMDG OQL ini juga menyerupai SQL declarative language yang menyediakan lingkungan yang luas untuk melakukan query objek database, termasuk high-level untuk kumpulan objek dan struktur objek.
OQL ini memiliki object extension untuk identitas objek, compleksitas objek, path expression, keterlibatan operasi, dan inheritance. OQL menjaga integritas objek dengan menggunakan method objek yang telah terdefinisi, bukan operator update. Namun, harus dikatakan bahwa OQL bukanlah sebuah bahasa yang lengkap karena tidak ada operator update seperti insert, delete yang secara eksplisit disediakan. Tapi untungnya OQL bisa meminta method state-altering (perubahan state) seperti create(), add(), delete(), dan lain-lain untuk mendapat fungsi yang tak sediakan tersebut.
Contohnya:
Person(name: “Atika”, birthdate: 11/25/1988, salary: 1000000)
untuk membuat objek person yang baru dan kita memerlukan atribut data.
OQL Query Forms
OQL adalah bahasa yang fungsional (expression-oriented), di mana setiap query adalah typed expression. Type ini bisa jadi atomic object, collection object, atau literal.
Ada 3 bentuk query dalam OQL:
1. Sebuah extent name mempunyai kumpulan objek yang akan mengembalikan kumpulan objek tersebut.
Contoh: person -> set<Person>
2. Sebuah objek yang telah diberi nama adalah query yang legal. Misal seorang karyawan mempunyai nama “budi”, dari situ didapatkan 2 query, yaitu objek itu sendiri dan subordinat nya, yang mengembalika tipe Person dan kumpulan objeknya.
Contoh: budi -> Person
budi.subordinates -> set<Person>
3. Query select mengembalikan sebuah tipe literal dari bag, set, atau list barang yang di-select dengan dibantu oleh ‘form’ dan ‘where’
Contoh:
SELECT <collection>
FROM {<collection> [<iterator var>]}*
[WEHERE <cond expr>]
[GROUP BY <group expr>]
[HAVING <cont expr>]
[ORDER BY <order cond>]
Jika benar-benar dicontohkan dalam bahasa OQL, akan mirip dengan bahasa SQL namun OQL mempunyai object extensions. Misal
select c.address
from Person p, p.children c
where p.address.street = “Bay Street” and
count (p.children) >=1 and c.address.city != p.address.city
Query ini akan mencari semua anak dari setiap orang yang tinggal di Bay Street yang memiliki paling tidak 1 anak, yang akan mengembalikan alamat dari anak yang tidak tinggal di kota yang sama dengan orang tuanya. Ini diarahkan dari kelas Person, dengan menggunakan referensi child untuk instansiasi lain dari kelas Person, lalu baru menggunakan kelas Address dan City.
Path Expression
OQL ini adalah bahasa yang navigational, yang artinya bahasa ini bisa mengikuti referensi dari objek yang di-retrive untuk mendapatkan objek lain yang diinginkan. Nah, path expression inilah yang merupakan mekanisme navigasinya.
Path expression dimulai dengan variable yang terinstansiasi oleh sebuah objek yang diikuti sebuah period(.) atau arrow(->), dan diikuti lagi oleh atribut atau nama hubungannya.
Misalkan p adalah variable yang terinstansiasi oleh type Person. 2 contoh path expression yang ekuivalen berikut mengembalikan kota di mana objek spouse tinggal.
p.spouse.address.city.name
p->spouse->address->city->name
Karena tadi kita sudah membahas bahasa C++ yang mempunyai sistem persisten untuk diterapkan dalam basis data, contoh implementasinya dalam OQL misalnya:
query untuk mendapatkan semua account yang dimiliki oleh orang tertentu, sebut saja “John” yang mempunyai balance besar dari 100.000 Rupiah. Berikut kodenya:
d_Set<d_Ref<Account>> result;
d_OQL_Query q1(“select a from Customer c, c.accounts a
where c.name=”John” and a.find_balance()>100″);
d_oql_execute(q1, result);
)
==================================================
Part 5 of Object Oriented Database (OODB) Exploration
05 Agustus 2009
Setelah mengenal OODB lebih jauh, sekarang kita akan melihat kelebihan dan kekurangannya.
Kelebihan OODB
1. Desain data yang bagus 🙂
Terkadang pada sistem yang dinamis, programmer merasa kesulitan dalam menangani masalah data. Dengan OODB, masalah ini bisa lebih dikurangi. Karena dengan orientasi obyek maka proses penyimpanan dan pengambilan data jauh lebih sederhana sehingga bisa menghemat waktu dan tenaga.
Konsep OO bisa membuat program dan data terintegrasi dengan baik. Paradigma OO dapat menyederhanakan application modelling, kebutuhan design tool serta visualisasi sisten dan desainnya. Dengan menggunakan, OODB kita tidak hanya mendapatkan persistensi data saja, melainkan juga keseluruhan obyek database, bahkan termasuk implemented behaviour-nya. Selain itu, kita dapat memanggil suatu method dari obyek tertentu pada database di server sehingga distribusi aplikasinya lebih mudah.
Dalam Relational Database (RDB), untuk melaksanakan hal ini kita harus memasukkan stored procedure atau suatu komponen obyek. Sehingga arsitektur dari aplikasi jadi lebih rumit dan membutuhkan keahlian pemrograman lebih lanjut.
2. Pembuatan aplikasi lebih sederhana
Dengan OODB kita dapat menyederhanakan pembuatan aplikasi dengan meminimalisasi penggunaan bahasa pemrograman dan implementasi teknologi yang dibutuhkan. Kadang kala, biaya suatu proyek bisa tinggi karena faktor teknis seperti penggunaan tool, bahasa pemograman, dan aplikasi yang bermacam-macam dalam satu lingkungan kerja. Dengan penyederhanaan pembuatan aplikasi ini, biaya keseluruhan bisa lebih ditekan pula.
Selain itu, kemampuan teknis yang dibutuhkanpun menjadi berkurang karena programmer cukup menguasai konsep dan bahasa OO (seperti C++ dan Java ^^) dengan sedikit tambahan mengenai koneksi ke database. Programmer bisa tinggal memfokuskan pada persistensi obyek dan tidak perlu lagi meguraikan obyek ke tabel, memikirkan relasi antar tabel, dan sebaliknya.
3. Kinerja tangguh
Pada produk ODBMS yang tepat dan sesuai dengan aplikasi yang dibuat, OODB dapat meningkatkan kinerja aplikasi dengan peningkatan yang tinggi.
Tak seperti RDB, Programmer tidak perlu memetakan data dengan objek lagi, menguraikan tabel ke objek, dan lain-lain. Tidak perlunya pemetaan dan pelaksanaan query-query ini membuat kinerja program jadi lebih cepat karena program langsung mengakses data dengan obyeknya…
Pada beberapa produk ODBMS bahkan dimungkinkan adanya client caching. Kecepatan yang dapat dihasilkan akan menjadi besar karena program hanya perlu mengakses cache dari database yang sudah ada di client.
Kelemahan OODB
Di balik kelebihannya, tentu saja OODB mempunyai kelemahan. Kelemahan OODB:
Pertama, hal yang bisa kita soroti adalah resiko migrasi dari RDB ke OODB atau sebaliknya. Cara penyimpanan dan pengambilan data pada OODB sangat berbeda dengan RDB. Demikian juga cara pengaksesannnya. Itu sebabnya, apabila kita bermigrasi dari RDB ke OODB, kita harus terus menggunakan OODB. Setelah mengimplementasikan OODB, sangat sulit untuk kembali ke RDB.
Kedua, tight application coupling. Pada banyak implementasi OODB, data berpasangan erat dengan aplikasinya sehingga sulit untuk dipisahkan. Hal ini menyederhanakan desain dan kode, tapi menghilangkan batas antara basis data dengan aplikasi. Juga menyebabkan suatu kendala baru bila kita ingin bermigrasi ke produk ODBMS yang berbeda atau kembali kedalam RDBMS.
Contoh tight coupling adalah bahasa COBOL di mana ada kesulitan untuk mengakses basis data COBOL dengan bahasa pemprograman lain.
Ketiga, kecacatan kinerja. Memang, dari kinerjanya yang tangguh dalam hal mengakses data secara efisien, namun pada kondisi tertentu mungkin saja OODB menghasilkan kinerja yang buruk. Misalnya OODB yang lemah dalam pelaksanaan ad-hoc query. Kehilangan arah data juga bisa menjadi masalah karena optimisasi dan fungsionalitas OODB biasanya ketinggalan dengan produk RDBMS yang telah lebih lama beredar di pasaran.
Beberapa implementasi OODB tidak menyediakan penguncian yang cukup kecil terhadap data akibatnya penguncian bisa saja terjadi pada kumpulan objek padahal yang dituju hanya satu objek tertentu saja.
Keempat, dukungan platform yang terbatas.
Pada dasarnya OODB dapat diterapkan pada bahasa pemrograman orientasi obyek apa saja, tapi produk ODBMS yang ada masih kebanyakan diorientasikan untuk digunakan dalam bahasa Java dan C++. Disamping itu juga belum banyak tersedia komponen untuk pengaksesan OODB untuuk bahasa pemrograman lainnya.
Bahkan, walaupun OODB diimplementasikan dengan Java, kita harus tetap mencari jaminan bahwa implementasi dapat diterapkan pada platfrom yang bermacam-macam meningat Java juga memiliki aneka nuansa dan keanehan-keanehan bila diterapkan pada lingkungan yang berbeda.
Kelima, query yang kompleks.
Terkadang, cara query pada OODB bisa berbeda-beda tergantung bahasa pemograman yang digunakan. Akses data juga tak bisa dilakukan dengan melihat ID-Object saja atau primary key saja, namun kadang juga berdasarkan range, pola, dll. Oleh sebab itu, OODB butuh logika yang mendalam pula.
Selanjutnya, orang yang mempunyai kemampuan spesifik OODB lebih sedikit daripada orang yang memahami RDB atau orang yang menguasai MS-Access, MS-SQL, Oracle, dll. Peralihan paradigma dari RDB ke OODB juga membutuhkan pelatihan khusus karena banyak perbedaan pendekatan seperti performa, join, locking, query, dsb.
Dari eksplorasi yang dilakukan, bisa ditarik kesimpulan:
1. OODB memodelkan data sebagai sebuah objek sehingga jika programmer yang ingin menambahkan tipe data baru dengan membuat proyek baru. Pengaksesan dan pengolahan data murni dilakukan dengan pemograman OO.
Hal ini tentu saja berbeda dengan RDB yang memodelkan data dengan tabel terformat. Tabel-tabel inilah yang berisi tipe data.
2. Melihat masih cukup banyaknya kekurangan OODB ini, sebelum memutuskan untuk memakai ODBMS ada baiknya mempertimbangkan kekurangan yang sudah diuraikan di atas. Saya sendiri pribadi masih menyukai RDB 🙂
3. Mempertimbangkan faktor kebutuhan dan ketersediaan aplikasi serta platform. (masih termasuk kekurangannya tadi).
Pada beberapa aplikasi tertentu penggunaan OODB mungkin sangat tepat. Sebaliknya untuk beberapa aplikasi lainnya OODB mungkin akan menjadi hambatan serius. Contohnya OODB tidak cocok digunakan untuk menyimpan data transaksi yang besar seperti data keuangan, kepegawaian dan data transaksi bank. Di sini mungkin lebih baik memilih RDB.
OODB bagus digunakan menggunakan tipe data multimedia dan data yang sifatnya kompleks.
DAFTAR REFERENSI
Heryanto, Bambang, “Esensi-esensi pemograman Java”, Penerbit Informatika, Bandung: 2007
http://www.geocities.com/a_alaydrus/oodb/bab2.html
http://www.cs.pitt.edu/~chang/156/19oodb.html
http://en.wikipedia.org/wiki/Object_database
http://archive.devx.com/dbzone/articles/sf0601/sf0601p.asp
You don’t have to be afraid of what you are.
There’s an answer if you reach into your soul
and the sorrow that you know will melt awayAnd then a hero comes along
with the strength to carry on
and you cast your fears aside
and you know you can survive.So, when you feel like hope is gone
look inside you and be strong
and you’ll finally see the truth
that a hero lies in you.It’s a long road when you face the world alone,
No one reaches out a hand for you to hold.
You can find love if you search within yourself
and the emptiness you felt will disappear.And then a hero comes along
with the strength to carry on
and you cast your fears aside
and you know you can survive.So, when you feel like hope is gone
look inside you and be strong
and you’ll finally see the truth
that a hero lies in you.
oh….Lord knows dreams are hard to follow,
But don’t let anyone tear them away.
Hold on, there will be tomorrow,
In time you’ll find the way
And then a hero comes along
with the strength to carry on
and you cast your fears aside
and you know you can survive.
So, when you feel like hope is gone
look inside you and be strong
and you’ll finally see the truth
that a hero lies in you
that a hero lies in … you
mmmm that a hero lies in…..you.
Object Oriented Database [by : Hendy]
June 10, 2009
Part 1 – Overview
10 Juni 2009
Kita telah mengenal konsep OO (Object-Oriented) pada mata kuliah Pemrograman Berorientasi Objek (IF2032). Oleh karena itu, tentu kita tidak akan memperoleh kesulitan dalam mempelajari Object Oriented Database. Konsep-konsep yang penting dalam OO antara lain :
- Kelas
Kelas merupakan suatu tipe baru yang didefinisikan oleh programmer. Dengan kata lain, Kelas adalah cetakan objek, suatu kelas bisa memiliki banyak objek. Setiap kelas memiliki atribut dan method. - Enkapsulasi
Enkapsulasi adalah pemisahan aspek-aspek eksternal objek yang dapat diakses dari rincian-rincian implementasi internal. Enkapsulasi meredam ketergantungan yang begitu besar dengan objek kelas lainnya. - Pewarisan
Pewarisan atau Inheritance adalah proses penciptaan kelas baru dengan mewarisi karakteristik kelas yang sudah ada, ditambah karakteristik unik kelas yang baru itu. Pewarisan mendukung penggunaan kembali (reusability) suatu kode. - Polimorfisme
Secara harafiah, Polimorfisme berarti banyak bentuk. Dalam konsep OO, objek-objek dikatakan polimorfik bila mempunyai antarmuka yang identik, damun mempunyai perilaku yang berbeda. Contoh mudahnya adalah dua buah objek dari kelas yang berbeda dapat memiliki nama method yang sama, namun algoritma methodnya berbeda.
Object Oriented Database adalah sebuah sistem database yang menggabungkan semua konsep penting dari object oriented tersebut dengan beberapa fitur tambahan antara lain :
- Unique object identifiers
- Persistent object handling
Teknologi ini mengintegrasikan kemampuan basis data (DBMS) dengan kemampuan pemrograman berorientesi objek (OOP). Sebuah Object Oriented Database Management System (ODBMS) membuat objek sebuah basis data terlihat seperti objek pemrograman pada beberapa bahasa pemrograman OOP. Sebuah ODBMS dapat memperluas kemampuan bahasa pemrograman dengan kemampuan basis data seperti data yang persistent secara transparan, kontrol konkurensi, recovery data, query asosiatif dan berbagai kemampuan basis data yang lain.
OODB atau ODBMS dirancang untuk bekerja pada bahasa pemrograman berorientasi objek seperti Java, C++ dan lain-lain. Bila kita ingin menyimpan objek pada program Java atau C++ ke dalam sebuah sistem basis data, kita dapat menggunakan basis data yang berorientasi kepada objek (ODBMS).
ODBMS sangat memudahkan programmer terutama yang terbiasa dengan OOP dalam mengolah data dan variabel dalam programnya. Kebanyakan programmer basis data menghabiskan cukup banyak waktu untuk merepresentasikan variabel atau objek pada programnya ke dalam struktur basis data.
Letak perbedaan utama ODBMS dengan sistem basis data konvensional adalah pada sistem basis data konvensional data direpresentasikan ke dalam bentuk tabel-tabel dengan kolom yang mewakili kategori dari data, dan baris yang berisi data itu sendiri. Sedangkan dalam ODBMS, data direpresentasikan sebagai sebuah objek, baik dalam hal pengaksesannya maupun dalam hal pemodelannya.
Part 2 – Kelebihan dan Kelemahan OODB
23 Juni 2009
OODB memang memiliki banyak keunggulan dibandingkan dengan RDB (Relational Database). Namun dewasa ini, OODB masih belum dapat menggantikan posisi RDB. Biarpun OODB memang teknologi baru yang sangat terkenal di kalangan ahli sistem basis data, namun para pembuat aplikasi yang belum begitu mengenal teknologi OODB ini masih lebih memilih menggunakan RDB yang sudah biasa mereka gunakan.
Para pembuat aplikasi harus menentukan akan memilih OODB atau RDB dalam proyek yang akan mereka kerjakan. Sebab setiap permasalahan memerlukan penanganan yang berbeda-beda. Bisa saja dalam suatu kasus, menggunakan OODB adalah pilihan yang terbaik, namun bisa juga sebaliknya.
Kelebihan OODB
- Desain yang indah
Banyaknya waktu dan tenaga yang terbuang dalam menangani data memang menjadi masalah yang umum dalam suatu sistem basis data. Dalam OODB masalah tersebut dapat diminimisasi dengan konsep berorientasi objek yang dimilikinya sebab dengan konsep OO, proses penyimpanan dan pengambilan data akan menjadi lebih sederhana. Selain mendapatkan persistensi data, dengan OODB kita juga mendapatkan persistensi keseluruhan obyek database, bahkan termasuk implemented behaviour-nya. Kita juga dapat dengan mudah memanggil suatu method dari objek tertentu pada database di server sehingga distribusi aplikasinya lebih mudah. - Penyederhanaan pembuatan aplikasi
Tanpa disadari, terkadang suatu proyek dapat melambung biayanya karena faktor teknis seperti penggunaan beberapa tool, bahasa program dan lingkungan dari aplikasi yang berbeda-beda. Belum lagi biaya pelatihan dan lain-lain. Dengan OODB kita dapat menyederhanakan pembuatan aplikasi dengan mengurangi penggunaan bahasa pemrograman dan teknologi yang digunakan. Programmer cukup menguasai konsep OO dan bahasa pemrograman OO dengan sedikit tambahan mengenai konektivitas aplikasi dengan database. Selain itu, programmer tinggal memfokuskan pada persistensi objek. - Kinerja yang tangguh
Dengan RDB seorang programmer harus menghabiskan waktu dan tenaga untuk memetakan data dengan objek, menguraikan tabel-tabel ke dalam objek dan sebagainya. Terkadang hal ini mencapai sepertiga atau bahkan separuh dari program itu sendiri. Hal ini tentunya akan menyebabkan kinerja menjadi lambat karena harus memetakan objek tersebut, belum lagi bila harus melaksanakan query-query yang kompleks. Masalah tersebut tidak dijumpai dalam OODB, karena dalam OODB, program mengakses data dengan objek nya secara langsung sehingga kinerja program akan lebih tinggi. Lebih dari itu, pada beberapa produk ODBMS bahkan dimungkinkan adanya client caching. Bayangkan kecepatan yang dapat dihasilkan bila program hanya perlu mengakses cache dari database yang sudah ada di client.
Kelemahan OODB
- Tight coupling
Coupling berarti keterkaitan antara aplikasi dan database. Tight coupling berarti keterkaitan yang kuat antara aplikasi dan database sehingga aplikasi dan database sulit dipisahkan. Sebenarnya tight coupling dapat menyederhanakan program dan desainnya, namun hal ini juga dapat menyebabkan hilangnya batasan antara aplikasi dan database, juga akan menimbulkan masalah baru bila akan migrasi ke OODB lainnya atau kembali ke RDB. - Kurangnya dukungan platform
Pada dasarnya OODB diterapkan untuk dapat berintegrasi dengan semua bahasa pemrograman berorientasi objek, namun sampai sekarang kebanyakan OODBMS hanya mendukung bahasa pemrograman C++ dan Java saja. - Sulit bermigrasi
Cara penyimpanan dan pengambilan data dalam OODB sangat berbeda dengan RDB. Begitu juga dengan cara pengaksesannya. Oleh karena itu, dibutuhkan komitmen yang kuat dalam memilih DBMS yang akan digunakan, sekali bermigrasi ke OODB, akan sulit untuk kembali ke RDB. - Kebutuhan ketrampilan
Karena OODB masih tergolong baru dan masih relatif jarang penggunaannya, cukup sulit menemukan orang yang memiliki pemahaman OODB bila dibandingkan dengan orang yang memiliki pemahaman RDB. Selain itu, untuk memahami OODB, diperlukan pelatihan khusus sebab terdapat banyak perbedaan pendekatan dengan RDB. - Query yang kompleks
Kemampuan logika yang mendalam sangat diperlukan dalam OODB. Masing-masing OODB dapat memiliki cara pemanggilan query yang berbeda-beda. Selain menggunakan object ID-nya saja, pengaksesan suatu data dapat menggunakan range, pola, dan berbagai kriteria lain yang mungkin kelihatan tidak berhubungan.
Part 3 – Object-Relational Database
10 Juli 2009
Setelah melihat kelebihan dan kelemahan OODBMS dibandingkan dengan RDBMS, tentu saja kita harus memikirkan matang-matang jenis DBMS apa yang akan kita gunakan. Namun ternyata terdapat DBMS lainnya yang merupakan gabungan atau dapat dikatakan sebagai jembatan yang menghubungkan OODBMS dan RDBMS.
ORDBMS (Object-Relational Database Management System) merupakan DBMS yang mirip dengan RDBMS, tapi model object-oriented seperti objek, kelas, dan pewarisan sudah didukung langsung dalam skema basis data dan bahasa query-nya. Selain itu, dia juga mendukung adanya tipe data buatan dan method.
Salah satu tujuan ORDBMS adalah menjembatani celah antara teknik pemodelan data konseptual seperti Entity-relationship diagram (ERD) and object-relational mapping (ORM), yang sering menggunakan kelas, pewarisan, dan basis data relasional, yang tidak langsung didukungnya. Selain itu, tujuan lain ORDMBS ini adalah menjadi penghubung antara teknik pemodelan berorientasi objek yang digunakan di bahasa pemrograman berorientasi objek seperti Java, C++, atau C#.
Bila produk RDBMS tradisional berfokus pada manajemen pengambilan data yang efisien dari himpunan tipe data yang terbatas, ORDBMS memungkinkan software developer untuk mengintegrasikan tipe objek buatannya sendiri beserta method yang sesuai ke dalam DBMS.
Banyak SQL ORDBMS yang beredar di pasaran sekarang yang telah didukung dengan user defined types (UDT) atau tipe buatan dan function. Sebagian ORDBMS (misalnya Microsoft SQL Server) memungkinkan function untuk ditulis dalam bahasa pemrograman berorientasi objek, tapi ini saja tidak membuatnya menjadi OODB, dalam OODB orientasi objek adalah fitur dari model data.
Perbandingan dengan RDBMS
RDBMS pada umumnya akan memiliki pernyataan SQL seperti ini :
CREATE TABLE Customers ( Id CHAR(12) NOT NULL PRIMARY KEY, Surname VARCHAR(32) NOT NULL, FirstName VARCHAR(32) NOT NULL, DOB DATE NOT NULL ); SELECT InitCap(Surname) || ', ' || InitCap(FirstName) FROM Customers WHERE Month(DOB) = Month(getdate()) AND Day(DOB) = Day(getdate())
Dapat juga dibuat menjadi function seperti di bawah ini :
SELECT Formal(Id) FROM Customers WHERE Birthday(Id) = Today()
Dalam ORDBMS kita dapat membuat tipe bentukan dan ekspresi seperti BirthDay() :
CREATE TABLE Customers ( Id Cust_Id NOT NULL PRIMARY KEY, Name PersonName NOT NULL, DOB DATE NOT NULL ); SELECT Formal(C.Id) FROM Customers C WHERE BirthDay (C.DOB) = TODAY;
Part 4 – Bahasa Query OODB
21 Juli 2009
Bahasa query dalam OODB merupakan pengembangan dari bahasa query SQL yang sudah kita kenal dalam RDB. Yang membedakannya adalah kita dapat membuat ADT atau tipe baru selain tipe-tipe primitif yang sudah ada seperti INTEGER dan VARCHAR.
Misalnya kita ingin membuat tipe baru yaitu MAHASISWA :
CREATE TYPE mahasiswa ( Nama CHAR(20), NIM INTEGER, Usia INTEGER, Alamat alamat )
Nama, NIM, dan Alamat merupakan properti atau atribut dari kelas Mahasiswa.
Dalam hal ini, alamat merupakan tipe bentukan lainnya seperti di bawah ini :
CREATE TYPE alamat ( Negara CHAR(20), Propinsi CHAR(20), Kota CHAR(20), KodePos INTEGER, Jalan CHAR(50) )
Untuk retrieve nama dan NIM mahasiswa yang tinggal di Bandung, kita gunakan syntax seperti ini :
SELECT Nama(m), NIM(m) FOR EACH mahasiswa m WHERE Kota(Alamat(m)) = 'Bandung'
NB : contoh-contoh di atas menggunakan bahasa query IRIS, salah satu OODBMS yang ada.
Part 5 – Kesimpulan
5 Agustus 2009
Setelah melakukan eksplorasi selama kurang lebih 8 minggu mengenai topik Object Oriented Database, dapat kita tarik beberapa kesimpulan akhir yaitu :
- OODB adalah salah satu jenis DBMS yang menggunakan konsep object oriented yang terdapat pada OOP
- Dibandingkan dengan RDB, OODB lebih menyerupai kondisi dunia nyata
- Dalam OODB, proses pengambilan dan penyimpanan data akan lebih mudah karena setiap data memiliki object-ID masing-masing
- OODB masih belum bisa menggantikan kedudukan RDB karena masih tergolong baru sehingga tidak banyak yang menguasainya
- Terdapat ORDBMS yang merupakan kombinasi antara OODB dan RDB
- Dalam OODB kita dapat membuat tipe bentukan baru yang berupa kelas dalam konsep object oriented
Dengan demikian berakhirlah tugas eksplorasi dengan topik Object Oriented Database, semoga tugas eksplorasi ini dapat bermanfaat bagi yang membacanya. Mohon maaf apabila dalam eksplorasi ini terdapat hal-hal yang kurang berkenan. Terima kasih kepada semua pihak yang telah mendukung saya dan kepada semua referensi dalam pengerjaan tugas ini. Saya berharap dengan berakhirnya tugas ini, saya dapat memulai tugas baru saya sebagai asisten lab. Basis Data. Sampai Jumpa ^^
Daftar Referensi :
http://en.wikipedia.org/wiki/Object_database akses : 8 Juni 2009
http://www.geocities.com/a_alaydrus/oodb/index.html akses : 10 Juni 2009
http://en.wikipedia.org/wiki/Object-relational_database akses : 10 Juli 2009
http://www.cs.pitt.edu/~chang/156/19oodb.html akses : 21 Juli 2009
Hariyanto, Bambang. 2007. Esensi-Esensi Bahasa Pemrograman Java. Penerbit Informatika.
Temporal Database
June 10, 2009
Post 1 (10 Juni 2009)
« Pengenalan Database Temporal:
Database temporal merupakan database non-relational yang terintegrasi dengan aspek waktu, misalnya model data temporal dan versi temporal dari bahasa query terstruktur.
Lebih spesifik lagi aspek temporalnya biasa sudah termasuk waktu yang valid dan waktu transaksi. Atribut-atribut ini muncul bersamaan pada form data bitemporal.
- Waktu yang valid ditunjukkan dengan periode waktu kejadian yang sama dengan waktu pada dunia sebenarnya
- Waktu transaksi adalah periode waktu saat menyimpan suatu kejadian ke database
- Data bitemporal mengkombinasikan waktu valid dan waktu transaksi
Keterangan: kedua periode waktu tidak harus sama untuk suatu kejadian yang sama. Misalkan kita menyimpan databse pada database temporal pada abad ke 18. Waktu yang valid adalah diantara 1701 dan 1800. Sedangkan waktu transaksi dihitung pada saat kita memasukan suatu kejadian ke dalam databse, contoh 21 Januari 1998.
« Mengapa Kita Butuh Database Temporal:
Sejak dua decade terakhir, model data relational sudah menjadi sangat popular karena simpel dan memiliki fondasi matematis yang solid. Namun, model data relational seperti yang dikatakan Codd[Cod70] tidak menyimpan address dari dimensi temporal suatu data. Data yang seharusnya dibedakan dari waktunya tetap diperlakukan sama dengan data lainnya. Hal ini tidak memenuhi aplikasi yang harus membedakan nilai data pada waktu lampau, saat ini, dan/atau data pada masa depan—padahal dikehidupan nyata kita akan sering berurusan dengan data seperti ini. Kenyataannya, kebanyakan aplikasi membutuhkan data temporal untuk keperluan tertentu.
« Tujuan Utama dari Database Temporal:
- Mengidentifikasi tipe data yang cocok dengan waktu
- Mencegah hilang/berubahnya deskripsi suatu objek tertentu
- Menyediakan aljabar query untuk mengatasi data temporal
- Tetap compatible dengan database lama yang tidak menggunakan data temporal
« Apa yang Dapat Kita Lakukan dengan Database Temporal:
- Mudah dalam mengerjakan data temporal
- Merecord setiap perubahan data dengan baik sekali
- Setiap pendeskripsian objek dapat didefinisikan tanpa ada perubahan yang tidak diinginkan
- Memiliki model relational untuk mendeskripsikan data temporal
- Memiliki aljabar query untuk mengatasi data temporal
- Tetap mampu mengatasi data static (tanpa dimensi waktu) pada database temporal
- Aljabar database yang lama tetap dapat berjalan di database temporal
- Aljabar query yang baru untuk mengkontrol dimensi waktu mirip dengan aljabar database yang lama
« Solusi lain tentang Database Temporal:
- Menambahkan waktu valid
- Menambahkan waktu transaksi
- Menambahkan kedua hal di atas
- Pendekatan lainnya
Post 2 (23 Juni 2009)
Untuk memperjelas pengertian mengenai database temporal, maka saya akan memasukan sebuah contoh yang membandingkan penanganan suatu kasus bila dibuat database secara biasa dan dengan database menggunakan database temporal.
Contoh kasus yang diambil berasal dari biografi singkat tokoh buatan bernama Joel Wahyudi. Joel Wahyudi lahir pada tanggal 3 April 1975 di rumah sakit Medicine County, sebagai anak dari Hendro Wahyudi dan Irma Wahyudi yang bertempat tinggal di Smallville. Hendro Wahyudi dengan bangga mendaftarkan kelahiran anak pertamanya tanggal 4 April 1975 di kota Smallville. Joel tumbuh besar menjadi seorang pelajar cemerlang dan lulus dengan sangat baik pada tahun 1993. Setelah kelulusan, ia pergi untuk hidup sendiri di kota Bigtown. Meski Joel pindah pada tanggal 26 Agustus 1994, ia lupa untuk mendaftarkan perubahan alamatnya secara resmi. Hingga akhirnya pada akhir musim, ibunya mengingatkan Joel untuk mendaftarkan kepindahannya, yang kemudian ia lakukan beberapa hari setelahnya yaitu pada 27 Desember 1994. Meskipun Joel memiliki masa depan yang sangat menjanjikan, namun kisahnya berakhir dengan tragis. Joel Wahyudi mengalami kecelakaan tertabrak truk pada 1 April 2001. Yang pada hari itu juga langsung dilaporkan berita kematiannya secara resmi.
«Menggunakan Database Standar:
Untuk menyimpan kehidupan Joel Wahyudi di sebuah (non-temporal) tabel database, kita menggunakan table Person(Name,Address). Untuk memudahkan, Name kita buat menjadi primary key dari tabel Person.
Ayah Joel secara resmi melaporkan kelahiran anaknya pada 4 April 1975. Hal ini berarti pada sebuah kantor di Smallville, dimasukan data berikut ke database pada tanggal saat itu: Person(Joel Wahyudi,Smallville). Perhatikan bahwa tanggalnya sendiri tidak dimasukan ke database. Setelah lulus kemudian Joel pindah, namun ia lupa mendaftarkan alamat barunya. Data milik Joel pada database tidak berubah sampai 27 Desember 1994, yaitu ketika akhirnya ia mendaftar ke kantor di Bigtown. Kantor di Bigtown mengupdate alamatnya di database. Tabel Person saat ini berisi Person(Joel Wahyudi,Bigtown). Perhatikan bahwa informasi alamat Joel di Smallville telah ditimpa. Maka tidak ada cara untuk mengakes informasi yang hilang tersebut melalui database. Setiap kantor yang mengakses databse pada 28 Desember 1994 akan mendapatkan Joel tinggal di Bigtown. Secara teknis: jika sebuah komputer melakukan query SELECT ADDRESS FORM PERSON WHERE NAME=’Joel Wahyudi’ pada 26 Desember 1994, menghasilkan: Smallville. Menjalankan query yang sama pada 2 hari selanjutnya menghasilkan Bigtown.
Sampai dengan kematian trgaisnya, database akan menyatakan Joel tinggal di Bigtown. Pada 1 April 2001 akhirnya petugas menghapus Joel Wahyudi dari databse. Maka pemanggilan query di atas tidak akan menghasilkan hasil apapun.
| Tanggal | Yang terjadi di dunia nyata | Perubahan di Database | Tampilan di Database |
| 3 April 1975 | Kelahiran Joel | Tidak ada | Tidak ada Person dengan nama Joel Wahyudi |
| 4 April 1975 | Hendro melaporakan kelahiran anaknya ke kantor secara resmi | Inserted:Person(Joel Wahyudi, Smallville) | Joel Wahyudi tinggal di Smallville |
| 26 Agustus 1994 | Setelah kelulusan, Joel pindah ke Bigtown, namun lupa untuk meregristasikan alamat barunya | Tidak ada | Joel Wahyudi tinggal di Smallville |
| 26 Desember 1994 | Tidak ada | Tidak ada | Joel Wahyudi tinggal di Smallville |
| 27 Desember 1994 | Joel mendaftarkan alamat barunya | Updated:Person(Joel Wahyudi, Bigtown) | Joel Wahyudi tinggal di Bigtown |
| 1 April 2001 | Joel meninggal | Deleted:Person(Joel Wahyudi) | Tidak ada Person dengan nama Joel Wahyudi |
Post 3 (1 July 2009)
«Menggunakan Database Temporal dengan Waktu yang Valid:
Waktu yang valid (valid time) yang berarti waktu sebernarnya di dunia nyata. Pad contoh di atas, tabel Person mendapat dua fields tambahan, yaitu Valid-From dan Valid-To, yang menjelaskan kapan Address seseorang berlaku di dunia nyata. Pada 4 April 1975, Hendro dengan bangga mendaftarkan kelahiran anak pertamanya. Maka petugas akan memasukkan data tersebut ke database yang menjelaskan Joel bertempat tinggal di Smallville sejak 3 April. Perlu diketahui meski data dimasukkan pada 4 April, namun database menjelaskan bahwa informasi tersebut berlaku sejak tanggal 3. Petugas belum mengetahui apakah atau kapan Joel akan berpindah ke tempat lain, sehingga pada field Valid-To di database diisi dengan infinity (∞). Pemasukkan data ke basisdata berupa:
Person(Joel Wahyudi, Smallville, 3-Apr-1975, ∞).
Pada tanggal 27 Desember 1994, Joel melaporkan alamat barunya di Bigtown yang sudah ia tinggali sejak 26 Agustus 1994. Petugas di kantor Bigtown tidak merubah alamat milik Joel di database. Sang petugas menambahkan yang baru:
Person (Joel Wahyudi, Big Town, 26-Aug-1994, ∞).
Masukan data milik Joel sebelumnya (Joel Wahyudi, Smallville, 3-Apr-1975, ∞) kemudian diupdate (tidak dihapus!). karena diketahui Joel sudah tidak tinggal di Smallville pada 26 Agustus 1994, maka kolom Valid-To dapat terisi. Database kemudian memiliki dua buah entry milik Joel
Person(Joel Wahyudi, Smallville, 3-Apr-1975, 26-Aug-1994).
Person(Joel Wahyudi, Bigtown, 26-Aug-1994, ∞).
Saat Joel meninggal, database diupdate sekali lagi. Entry terbaru akan diupdate menyatakan bahwa Joel tidak tinggal di Bigtown lagi. Tidak ada entry yang ditambahkan karena tidak pernah dilaporkan surge sebagai alamat baru. Maka database sekarang akan seperti ini
Person(Joel Wahyudi, Smallville, 3-Apr-1975, 26-Aug-1994).
Person(Joel Wahyudi, Bigtown, 26-Aug-1994, 1-Apr-2001).
«Menggunakan Database Temporal dengan Waktu Transaksi:
Waktu transaksi adalah penggunaan database temporal menggunakan waktu pada saat transaksi dilakukan. Dengan ini kita dapat menggunakan queri-queri yang menampilkan status database pada waktu tertentu. Maka ada dua tambahan kolom di tabel Person: Transaction-From dan Transaction-To. Transaction-From merupakan waktu saat transaksi dilakukan, sedangkan Transaction-To adalah waktu transaksi dibatalkan (atau menggunakan tak terhingga jikan belum akan dibatalkan).
Apakah yang akan terjadi jika alamat seseorang yang ada di database merupakan alamat yang salah? Anggap seorang petugas secara tidak sengaja memasukkan alamat atau tanggal yang salah? Atau, anggap orang yang memasukkan data berbohong ketika memberi informasi untuk keperluan tertentu. Setelah mengetahui data yang benar, maka petugas harus kembali mengupdate database tersebut.
Sebagai contoh, dari 1 Juni 1995 hingga 3 September 2000 Joel Wahyudi pindah ke Beachy. Namun untuk menghindari membayar pajak kota Beachy yang sangat mahal, Joel tidak pernah melapor ke yang berwewenang. Akhirnya, hal tersebut terungkap pada 2 Februari 2001 saat ada pengecekan pembayaran pajak, bahwa dia sebenarnya tinggal di Beachy selama ini, maka para petugas mengupdate database menjadi seperti ini:
Person(Joel Wahyudi, Bigtown, 26-Aug-1994, 1-Jun-1995).
Person(Joel Wahyudi, Beachy, 1-Jun-1995, 3-Sep-2000).
Person(Joel Wahyudi, Bigtown, 3-Sep-2000, 1-Apr-2001).
Maka 2 data yang sudah ada di update, dan sebuah data baru dimasukkan menyimpan keberadaannya di Beachy.
Bagaimanapun, hal ini tidak meninggalkan catatan di database yang menyatakan Joel tinggal di Bigtown dari 1 Juni 1995 hingga 3 September 2000, yang mungkin sangat penting untuk alasan mengaudit data (atau untuk menjadi bukti pada investigasi kantor pajak). Di sini kita dapat melihat waktu transaksinya. Kita harus menyimpan setiap data ketika dimasukkan dan ketika dibatalkan. Maka dari itu, kita memperoleh data seperti berikut:
Person(Joel Wahyudi, Smallville, 3-Apr-1975, ∞, 4-Apr-1975, 27-Dec-1994).
Person(Joel Wahyudi, Smallville, 3-Apr-1975, 26-Aug-1994, 27-Dec-1994, ∞ ).
Person(Joel Wahyudi, Bigtown, 26-Aug-1994, ∞, 27-Dec-1994, 2-Feb-2001 ).
Person(Joel Wahyudi, Bigtown, 26-Aug-1994, 1-Jun-1995, 2-Feb-2001, ∞ ).
Person(Joel Wahyudi, Beachy, 1-Jun-1995, 3-Sep-2000, 2-Feb-2001, ∞ ).
Person(Joel Wahyudi, Bigtown, 3-Sep-2000, ∞, 2-Feb-2001, 1-Apr-2001 ).
Person(Joel Wahyudi, Bigtown, 3-Sep-2000, 1-Apr-2001, 1-Apr-2001, ∞ ).
Jadi, kita tidak hanya menyimpan apa yang terjadi di waktu yang berbeda, tetapi kita juga menyimpan data yang berubah secara resmi pada waktu yang berbeda.
Permasalah utama pada database dengan waktu transaksi adalah saat mengembangkan queri-queri temporal dibawah penggunaan skemanya. Untuk mencapai pengarsipan data yang sempurna, sangat penting untuk menyimpan data dibawah skema awal ketika database dibuat. Namun, sesimpel apapun queri temporal, riwayat sebuah atributnya tetap butuh ditulis manual di setiap versi skemanya, dan mungkin ratusan kasus seperti pada kasus MediaWiki (http://yellowstone.cs.ucla.edu/schema-evolution/index.php/Schema_Evolution_Benchmark). Proses ini membutuhkan usaha yang sangat besar dari pengguna untuk merapihkan database tersebut. Penyelesaian umumnya dilakukan dengan menyediakan penulis queri secara otomatis.
Post 4 (24 July 2009)
Sebelum melanjutkan ke topik selanjutnya, perlu diingat satu konsep penting tentang ke presisian waktu yang di simpan di database temporal. Konsep ke presisian dari sebuah database temporal disebut granularity of the time (serpihan waktu). Granularity merupakan unit terkecil durasi waktu yang disimpan pada database temporal kita. Contoh serpihan waktunya yaitu satu hari, satu jam, atau satu detik.
«Konsep Utama dalam Memahami Database Temporal
Telah kita ketahui dua tipe waktu utama dalam konsep database temporal, yaitu waktu transaksi (transaction time) dan waktu yang valid (valid time), memungkinkan 3 bentuk database temporal : Historical, Rollback, dan Bitemporal. Sebuah database temporal historical dapatmensuport valid time, tapi tidak dapat menggunakan transaction time. Tipe kedua yaitu rollback database, database ini kebalikannya dari database historical, yaitu menggunakan transaction time dan tidak dapat menggunakan valid time. Rollback database sangat berguna dalam data recovery setelah jika terdapat kerusakan pada temporal database. Sebuah database rollback juga diperlukan jika database tidak di proteksi untuk menjaga keamanan data. Sehingga saat ini pada pasar tingkat dunia, minimal biasanya menyediakan beberapa fitur rollback.
Temporal database yang sebenarnya adalah database bitemporal. Database ini mensuport keduanya, yaitu transaction time dan valid time, sehingga menghasilkan kombinasi bentuk database historical dan rollback. Database bitemporal mampu mengatasi permasalahan dimensi waktu; dalam tingkat DBMS yaitu transaction time, dalam tingkat data yaitu valid time, dan dalam tingkat user menggunakan user-defined time.
«Tujuan Utama bagi Database Temporal… Kemampuan Query
Salah satu faktor terpenting dalam menggunakan database yang mensuport dimensi temporal, yaitu kemampuan untuk menjalankan data dengan query. Saat ini yang umum digunakan untuk database conventional (relational) adalah Structured Query Language atau yang biasa kenal dengan SQL. SQL sudah menjadi bahasa standar di industri untuk Relational Database Management Systems (RDBMS) karena kemudahan dalam menggunakannya yang sintaksnya mirip dengan bahasa Inggris langsung. SQL termasuk user friendly dan dapat digunakan untuk berbagai keperluan. Bagaimanapun penambahan element temporal ini meningkatkan kompleksitas query pada data temporal. Dengan penambahan elemen time, dalam kemampuannya saat ini SQL tidak dapat memproses query query tersebut seperti biasanya pada kondisi database klasik (relational). Bahasa query yang baru atau perluasan dari SQL sangat diperlukan di sini. Perlu diketahui, salah satu permasalahan terbesar yang diteliti saat-saat ini adalah di bagian temporal database. Hari-hari ini, tidak sedikit bahasa-bahasa dan perluasan bahasa-bahasa query yang mengajukan dan membahas topik ini. Topik ini cukup memerlukan perhatian khusus, dan salah satu contohnya akan diberikan berikut ini.
Bahasa query temporal yang baru harus dapat mensuport kemampuan SQL tanpa mengurangi kemampuan sebelumnya. SQL sudah memberi bantuan yang sangat besar dan mendominasi RDBMS saat ini karena, seperti yang kita ketahui sebelumnya, SQL cocok untuk banyak keperluan bisnis dan merupakan bahasa yang user friendly. Salah satu bahasa query yang paling diharapkan adalah bahasa query yang mensuport dimensi waktu dan tetap memungkinkan user memasukan query tanpa menetapkan dimensi waktunya (hal tersebut menhindari biaya lebih). Dan bahasa tersebut bukanlah sebuah bahasa yang baru, melainkan perluasan dari bahasa SQL. Satu contoh yang paling menarik adalah TSQL. TSQL yang merupakan Temporal Structured Query Language dapat berjalan tanpa harus memasukkan kriteria waktu. Karena demikian, ketentuan-ketentuan utama dari query TSQL masih sama dengan ketentuan-ketentuan di SQL: yaitu ‘SELECT’ dan ‘FORM’. Jika perlu juga terdapat ‘WHERE’, ‘GROUP BY’, ‘HAVING’, dan ‘ORDER BY’. Kriteria tambahan pada TSQL dapat berupa ‘WHEN’ atau ‘WHILE’. Kedua nama query tersebut bermaksud menjelaskan perbedaan kondisi waktu. Klausa ‘WHEN’ menjelaskan perincian “sepotong waktu” untuk data yang valid atau tidak valid tergantung hasil yang diinginkan. Saat ini, pengajuan untuk menambahkan TSQL ke ANSI dan ISO milik SQL standar sedang dipertimbangkan oleh pihak-pihak yang mengaudit.
Post 5 (8 Agustus 2009)
Setelah membahas teori-teori mengenai database temporal, pada bagian terakhir ini saya akan menggabungkan bagian teori dengan bagian praktiknya langsung mengenai database temporal. Di sini,akan dijelaskan mengenai beberapa tipe bisnis yang dapat mendapat keuntungan lebih dengan bantuan database temporal.
«Data Warehouse
Data warehouse atau pergudangan data bukan merupakan bisnis per se (bukan bisnis itu sendiri, tapi mengambil dari bisnis lain). Data warehouse ini merupakan usaha yang sangat luas, yaitu bisnis yang diperuntukan menyimpan seluruh informasi dari beberapa perusahaan. Data warehouse terbukti sangat berguna sebagai tempat penyimpanan informasi yang dikumpulkan dengan tools data mining dan digunakan untuk sumber informasi. Seperti yang sudah kita ketahui, elemen waktu sangat penting untuk berbagai bisnis, dan dalam sebuah data warehouse dimensi waktu dapat disimpan dan digunakan dalam peng query an data. Sebenarnya apa yang data warehouse lakukan dengan adanya database temporal? Menurut Ralph Kimball, setiap data warehouse memiliki dimensi waktu yang membuat setiap data warehouse menjadi database warehouse [Kimball 1997],[Snodgrass 1998].”Dimensi waktu adalah unik dan merupakan dimensi yang kuat dalam setiap kumpulan data dan usaha data warehouse”[Kimball 1997].
«Laboratorium Ilmiah
Jenis bisnis yang kedua adalah lab ilmiah (scientific laboratory). Setiap lab tentu melakukan banyak uji coba dan banyak versi untuk percobaan yang sama, dan setiap percobaan sering kali melibatkan urutan waktu yang sangat teliti. Agar informasinya tidak ada yang hilang, tentunya harus disimpan dalam sebuah database. Karena elemen waktu di test ini jelas tidak bisa dihilangkan, sehingga informasi yang disimpan di sini harus disimpan dalam database temporal. Satu keuntungan dalam menyimpan informasi ujicoba ilmiah pada temporal database yang mendukung bahasa query temporal adalah, sebuah pola baru dan pengetahuan baru dapat digali dari basis data [Loomis 1997].
«Sales dan Marketing
Kedua bisnis ini sangat berkantung pada temporal database, karena keberhasilan sales dan marketing sangat bergantung pada waktu yang tepat. Waktu untuk pendekatan dengan pelanggan dan kapan untuk mengiklankan di lokasi tertentu sangat diperlukan, dan kemampuan untuk meramalkan informasi ini jauh lebih baik disediakan database temporal daripada database klasik biasa.
«Multimedia
Jenis bisnis yang terakhir adalah multimedia. Multimedia merupakan salah satu area bisnis yang paling cepat berkembang saat ini, terutama melalui jalus internet. Seseorang saat ini dengan mudah menonton film dari internet, dimana gambar video tersebut sudah tersimpan di database multimedia yang harus disinkronisasikan dengan data audio yang mungkin berada di database yang sama atau berbeda. Pengsinkronisasian ini, seperti kata tersebut sendiri, jelas melibatkan elemen waktu. “Karen multimedia berbasis waktu, sinkronisasi sangat di butuhkan. Jika diimplementasikan dengan baik, maka komponen-komponen media tersebut akan ditampilkan dengan ketepatan dari sinkronisasi yang baik[David]”. “Objek-objek multimedia memiliki relasi dan ruang temporary yang harus dijaga saat ditampilkan beberapa data memiliki batasan waktu nyata (real time) saat menyampaian ke stasiun clien[Ozsu]”. Karena itu, database untuk multimedia, seperti data warehouse, merupakan instance dari database temporal juga.
Sebagai penutup, akan dibahas sedikit mengenai database temporal di masa mendatang. Dengan meningkatnya persaingan di lingkungan bisnis, pengetahuan akan informasi antar organisasi menjadi sumber yang berharga. Salah satu elemen kunci dari informasi ini adalah dimensi waktu. Untuk mendapatkan informasis ini, dalam bisnis harus digunakan database temporal. Dalam menerapkan kemampuan menyimpan variable waktu pada bisnis yang ada, akan terdapat dua hal yang berpengaruh. Pertama, kebanyakan produsen basis data komersial akan berlomba-lomba memasukkan kemampuan temporal data di produk basis data mereka. Kedua, extension temporal database akan dimasukkan ke ANSI dan ISO SQL standar yang sudah ada. Hal ini akan memungkinkan pengguna untuk mengambil keuntungan dari fitur temporal baru pada produk database yang biasa mereka gunakan. Pada titik ini, sebagian besar dari produsen database komersil akan menggunakan database temporal. Hal ini memungkinkan pengetahuan akan informasi yang lebih lengkap dan lebih baik dapat disimpan dan diambil dari database temporal, yang membuat bisnis-bisnis beralih menggunakan temporal database untuk bersaing dengan bisnis lainnya.
— — — @ @ @ — — —
DAFTAR PUSTAKA
http://www.cs.aau.dk/~csj/Thesis/pdf/chapter1.pdf, waktu akses: 10 Juni 2009
http://www.csie.ntu.edu.tw/~hh_lee/temporal/introduction.html, waktu akses: 10 Juni 2009
http://en.wikipedia.org/wiki/Temporal_database, waktu akses: 10 Juni 2009
http://www.csie.ntu.edu.tw/~tempdb2007/, waktu akses: 10 Juni 2009
http://citm.utdallas.edu/publications/whitepapers/wp_temporaldb.htm, waktu akses : 24 July 2009
http://www.dbdebunk.com/page/page/2317382.htm, waktu akses: 23 Juni 2009
Data Mining — Firdi
June 10, 2009
Who(ever) has information fastest and uses it wins
-Don McKeough, former president of Coca-Cola
Post I (10 Juni 2009)
Postingan pertama ini akan membahas latar belakang, definisi, dan fungsi dari data mining
Apa yang Melatarbelakangi Munculnya Data Mining?
Pada beberapa tahun belakangan ini telah terjadi perkembangan yang sangat pesat terhadap teknologi pengoleksian dan penyimpanan data. Perkembangan teknologi tersebut memungkinkan pengumpulan dan penyimpanan data dengan lebih cepat, kapasitas yang lebih besar, dan harga yang lebih murah. Pada akhirnya perkembangan teknologi tersebut menimbulkan penumpukan koleksi data, misalnya: data transaksi penjualan pada sebuah swalayan, data pasien pada rumah sakit, data rekening pada bank, dan sebagainya. Ukuran basis data meningkat baik dalam jumlah record (baris data) maupun jumlah atribut pada record. Hal ini didukung oleh perkembangan perangkat keras dan teknologi basis data yang memungkinkan penyimpanan dan pengaksesan data secara efisien dan murah. Tetapi kecepatan bertambah banyaknya data tersebut tidak diimbangi dengan banyaknya penarikan informasi dari data tersebut. Jadi bisa dikatakan kita kaya akan data, tetapi miskin akan informasi.

Kumpulan data jika dibiarkan begitu saja tidak dapat memberikan nilai tambah berupa pengetahuan yang bermanfaat. Pengetahuan yang bermanfaat ini misalnya, dari basis data penjualan pada perusahaan produk konsumen, dapat diperoleh pengetahuan tentang hubungan antara penjualan barang tertentu dan golongan konsumen dengan demografi tertentu. Pengetahuan ini dapat digunakan untuk melakukan promosi penjualan baru yang keuntungannya dapat diprediksi relatif terhadap promosi pemasaran lainnya. Basis data seringkali merupakan sumber daya potensial tidak aktif yang sebenarnya dapat menghasilkan manfaat yang besar.
Secara konvensional, untuk memperoleh pengetahuan dari data dilakukan analisis dan interpretasi secara manual. Namun analisis data manual sifatnya lambat, mahal, dan sangat subjektif. Dengan fakta bahwa volume data sangat besar (hingga jutaan record dan ratusan atribut pada tiap record dalam basis data), penggunaan analisis data manual menjadi sangat tidak praktis, sehingga perlu beralih menggunakan teknik komputasi. Proses pencarian pengetahuan bermanfaat dari data menggunakan teknik komputasi dikenal dengan istilah Knowledge Discovery in Databases (KDD). Definisi KDD adalah proses nontrivial untuk mengidentifikasi pola dari data, yang valid, baru, berpotensi menjadi pengetahuan yang bermanfaat, dan dapat dimengerti.
Jadi, Apa yang Dimaksud Dengan Data Mining?
Ada sekumpulan orang yang menganggap data mining sebagai sinonim dari KDD. Tetapi ada juga yang menganggap data mining adalah salah satu langkah khusus dalam proses KDD, yaitu aplikasi dari algoritma spesifik untuk mengekstrak pola (atau model) dari data. Selengkapnya, langkah-langkah dalam KDD adalah (seperti yang ditunjukkan di gambar) :

1. Selection
Selection adalah penyiapan data target yang digunakan untuk pencarian pengetahuan.
2. Preprocessing
Pada langkah ini dilakukan proses-proses pendahuluan meliputi pembersihan data (data cleaning), pengumpulan informasi yang diperlukan untuk memodelkan, penentuan strategi untuk menangani field data yang hilang, dan pencatatan informasi urutan waktu dan perubahan yang diketahui.
3. Transformation
Langkah ini meliputi penentuan fitur penting untuk merepresentasikan data bergantung pada tujuan, dan menggunakan reduksi dimensionalitas atau metode-metode transformasi untuk mengurangi banyaknya variabel efektif di bawah pertimbangan, atau menemukan representasi invarian bagi data
4. Data Mining
Data mining merupakan pencarian pola dalam bentuk representasi tertentu seperti Decision Tree, Neural Network, Rule Induction, Bayesian Network, K-Means Clustering, dll. Sebelum data mining dilakukan, terlebih dahulu perlu dipilih sebuah data mining task, selanjutnya dipilih sebuah representasi model yang sesuai dengan task tersebut, dan kemudian ditentukan algoritma untuk menemukan model.
Pemilihan sebuah data mining task disesuaikan dengan tujuan proses KDD yang telah ditentukan di awal. Data mining task antara lain :
- klasifikasi : memetakan (mengklasifikasikan) data ke dalam satu atau beberapa kelas yang sudah didefinisikan sebelumnya.
- regresi : memetakan sebuah item data pada sebuah variabel prediksi nilai nyata.
- clustering : memetakan data ke dalam satu atau beberapa kelas kategori (atau cluster) dimana kelas-kelas tersebut harus ditentukan dari data, tidak seperti klasifikasi dimana kelas didefinisikan sebelumnya.
- peringkasan : menemukan sebuah deskripsi kompak bagi sebuah subset data.
- pemodelan kebergantungan : menemukan model yang menggambarkan kebergantungan signifikan di antara variabel.
- deteksi perubahan dan deviasi : mencari perubahan yang paling signifikan dalam data dari pengukuran atau nilai normal sebelumnya.
5. Interpretation/Evaluation
Pada langkah ini dilakukan interpretasi terhadap pola yang dihasilkan untuk mendapatkan pengetahuan. Dimungkinkan juga untuk kembali ke langkah-langkah sebelumnya.
Apa fungsi Data Mining?
Secara umum fungsi proses data mining dapat diklasifikasikan dalam dua kategori : deskriptif dan prediktif. Fungsi prediktif menyediakan aturan-aturan global yang dapat diaplikasikan terhadap basis data. Aplikasi yang dimaksudkan meliputi prediksi suatu variabel tertentu jika diketahui suatu informasi pendukung. Sedangkan fungsi deskriptif bertujuan untuk menyediakan deskripsi dari data sumber yang tersedia. Deskripsi tersebut disediakan dalam bentuk ringkasan padat yang memberikan informasi berupa cluster, keterhubungan, asosiasi maupun bentuk-bentuk lainnya.
Post II (24 Juni 2009)
Pada postingan ini akan dibahas salah satu teknik dasar dari data mining yaitu mencari asosiasi antar data serta memperkenalkan market basket analysis.
Apa Beda DBMS dan Data Mining?
DBMS merupakan kumpulan query berdasarkan data yang disimpan, contoh
- Angka penjualan bulan lalu untuk tiap produk
- Daftar pembeli yang dikelompokkan berdasarkan umurnya
- Daftar pelanggan yang membeli di toko dengan jumlah di atas 10 kali dalam sebulan
Sedangkan data mining merupakan penarikan informasi dari data yang disimpan misalnya
- Pada kisaran umur dan pendapatan berapakah pelanggan banyak membeli TV?
- Barang apakah yang kemungkinan akan juga dibeli pelanggan jika ia membeli komputer?
Pada data seperti apakah data mining bisa diterapkan?
Secara prinsip, data mining dapat diterapkan pada banyak jenis basis data, seperti relational database, data warehouse, transactional, dan object-relational database. Pola data yang menarik juga dapat diambil dari jenis repository informasi yang lain termasuk spatial, time-series, sequence, text, multimedia, legacy database, data stream, dan World Wide Web. Tetapi teknik data mining bisa berbeda untuk tiap sistem repository.
Pola apa saja yang dapat diambil dari data?
Ada banyak jenis pola data, beberapa diantaranya yaitu itemset,subsequence, dan substructure. Itemset merupakan kumpulan barang yang sering muncul dalam data transaksi, seperti susu dan roti. Sedangkan subsequence merupakan pola pada data yang sekuensial, misalnya pola bahwa pembeli cenderung membeli sebuah PC, diikuti dengan sebuah kamera digital, dan kemudian sebuah memory card. Substructure merupakan pola dengan bentuk struktural seperti grafik atau pohon, yang biasa digabungkan dengan itemset atau subsequence. Jika sebuah substructure sering muncul, maka disebut pola terstruktur. Dari pola-pola tersebut dapat ditemukan hubungan antar data yang menarik. Bentuk pengambilan pola itemset yang paling awal adalah market basket analysis.
Market Basket Analysis?
Ini adalah proses yang menganalisa kebiasaan pembeli dengan menemukan hubungan antara barang yang berbeda pada keranjang belanja(market basket) mereka. Penemuan hubungan tersebut dapat membantu penjual untuk mengembangkan strategi penjualan dengan mempertimbangkan barang yang sering dibeli bersamaan oleh pelanggan. Sebagai contoh, bila pembeli membeli susu, seberapa besar kemungkinan mereka juga akan membeli roti (roti jenis apakah itu) pada transaksi yang sama.

Informasi seperti itu akan membantu penjual untuk meningkatkan angka penjualan. Untuk lebih jelasnya dapat dilihat pada contoh berikut ini:
Misalnya pada sebuah toko elektronik, untuk menjawab pertanyaan “Barang-barang apa saja yang kemungkinan dibeli pada kunjungan yang sama?” Untuk menjawab pertanyaan ini market basket analysis bisa dilakukan pada data transaksi pembelian pada toko tersebut. Hasilnya bisa diterapkan untuk berbagai perencanaan penjualan misalnya dalam mendesain layout toko. Ada 2 strategi:
- Barang-barang yang sering dibeli bersamaan ditempatkan berdekatan.
Hal ini meningkatkan kemungkinan barang-barang tersebut dibeli bersamaan.
Contoh: Jika pelanggan yang membeli komputer cenderung membeli antivirus juga, maka dengan menempatkan keduanya berdekatan, maka pembeli yang membeli komputer begitu melihat antivirus kemungkinan akan terpikir bahwa ia juga butuh antivirus sehingga membeli keduanya.
- Barang-barang tersebut justru diletakkan berjauhan.
Ini agar pelanggan yang membeli barang-barang tersebut mungkin tertarik untuk membeli juga barang yang lain ketika berjalan.
Contoh: Setelah membeli komputer yang mahal, seorang pembeli kemungkinan mengamati sistem keamanan rumah (karena takut computer mahalnya dicuri :P) yang dijual selagi menuju tempat antivirus berada sehingga kemungkinan membeli sistem keamanan rumah juga.
Pola hubungan ini direpresentasikan dalam bentuk apa?
Pola-pola hubungan ini bisa direpresentasikan dengan association rule yang bisa dilihat dari contoh berikut ini.
Contoh : Misalnya kita sebagai manager pemasaran dari sebuah toko elektronik serba ada, kita ingin menentukan barag-barang mana yang sering dibeli bersamaan pada transaksi yang sama. Misalnya diambil dari basis data perusahaan kita ditemukan
beli(X,”komputer”)→beli(X,”software”) [support = 1%, confidence = 50%]
Dimana X adalah variable yang mewakilkan pembeli. Confidence = 50 % berarti bila ada seorang pembeli yang membeli sebuah komputer, maka ada 50% kemungkinan dia akan membeli software juga. 1% support berarti 1% dari semua transaksi yang diteliti menunjukkan bahwa komputer dan software dibeli bersamaan.
Dari data-data yang ada bisa juga ditemukan hubungan seperti ini:
umur(X,”20..29”)^income(X,”2000K..3000K”)→membeli(X,”CD player”) [support=2%, confidence=60%]
Hubungan tersebut menunjukkan pengunjung toko kita yang dijadikan sampel, 2% diantaranya adalah berumur 20 sampai 29 tahun dengan pendapatan sekitar 2 juta sampai 3 juta membeli sebuah CD player. Ada 60% kemungkinan pembeli pada umur ini dan kelompok pendapatan ini akan membeli sebuah CD player.
Hubungan seperti ini biasa tidak dianggap bila hubungan tersebut tidak memenuhi baik ambang minimum support dan ambang minimum confidence.
Post III (7 Juli 2009)
Pada postingan ini akan dibahas metode efisien dalam data mining untuk itemset dasar dari transactional database, dan menunjukkan bagaimana menyimpulkan hubungan dari itemset tersebut.
Algoritma paling dasar untuk mencari itemset yang sering muncul (disebut frequent itemset) adalah algoritma Apriori.
Algoritma Apriori?
Algoritma ini diajukan oleh R. Agrawal dan R. Srikant tahun 1994. Apriori melakukan pendekatan iterative yang dikenal dengan pencarian level-wise, dimana k-itemset digunakan untuk mengeksplorasi (k+1)-itemset. Pertama, kumpulan 1-itemset ditemukan dengan memeriksa basis data untuk mengakumulasi penghitungan tiap barang, dan catat barang tersebut. Hasilnya dilambangkan dengan L1. Selanjutnya, L1 digunakan untuk mencari L2, kumpulan 2-itemset yang digunakan untuk mencari L3, dan seterusnya sampai tidak ada k-itemset yang dapat ditemukan. Penemuan Lk memerlukan pemeriksa keseluruhan basis data.
Untuk menambah efisiensi dari pencarian frequent itemset, digunakan kaidah Apriori yang berbunyi “Semua bagian tidak kosong dari frequent itemset juga frequent”.
Untuk lebih jelasnya mari kita lihat di contoh berikut :
Diketahui basis data transaksi D sebagai berikut:
| ID Transaksi | ID Barang yang dibeli |
| T100 | I1,I2,I5 |
| T200 | I2,I4 |
| T300 | I2,I3 |
| T400 | I1,I2,I4 |
| T500 | I1,I3 |
| T600 | I2,I3 |
| T700 | I1,I3 |
| T800 | I1,I2,I3,I5 |
| T900 | I1,I2,I3 |
- Pada iterasi pertama dari algoritma ini, setiap barang adalah anggota himpunan kandidat 1-itemset, C1. Algoritma ini memeriksa seluruh transaksi untuk menghitung jumlah kemunculan setiap barang
- Misalkan jumlah kemunculan minimum yang dibutuhkan adalah 2. Himpunan frequent 1-itemset, L1, maka dapat ditentukan yaitu terdiri dari kandidat 1-itemset yang jumlah kemunculannya memenuhi syarat.
- Untuk mencari himpunan frequent 2-itemset, L2, algoritma ini menggunakan L1L1 untuk menghasilkan kandidat 2-itemset, C2.
- Berikutnya data dalam D dibaca untuk dicatat akumulasi kemunculan barang di C2.
- Himpunan frequent 2-itemset, L2, kemudian ditentukan, terdiri dari kandidat 2-itemset dalam C2 yang memenuhi batas minimum.
- Berikutnya adalah mencari kandidat 3-itemset, C3. Seperti mencari kandidat C2, C3=L2L2={{I1,I2,I3,I5},{I2,I4,I5}}. Berdasarkan kaidah Apriori, kita dapat menentukan 4 kandidat berikutnya tidak mungkin frequent sehingga menghemat iterasi yang tidak perlu untuk mencari jumlah mereka ketika membaca D untuk menentukan L3.
- D dibaca untuk menentukan L3, yang terdiri dari kandidat 3-itemset dalam C3 yang memenuhi batas minimum yaitu {{I1,I2,I3},{I1,I2,I5}}.
- L3L3 untuk menghasilkan kandidat 4-itemset, C4. Walaupun hasilnya adalah {{I1,I2,I3,I4,I5}}, itemset ini tidak berlaku karena subset nya {{I2,I3,I5}} tidak frequent. Jadi, C4 = {}, dan algoritma ini berhenti.


Dari hasil yang diperoleh, bagaimana membuat Association Rule nya?
Setelah hasilnya diperoleh, langsung saja dibuat association rule yang kuat dari hasil tersebut (dimana association rule yang kuat memenuhi baik ambang minimum support dan ambang minimum confidence). Ini bisa didapat dari persamaan berikut:

Dimana support_count(A U B) adalah jumlah transaksi yang mengandung itemset A U B, dan support_count(A) adalah jumlah transaksi yang mengandung itemset A. Berdasarkan persamaan ini, association rule bisa didefinisikan sebagai berikut:
- Untuk setiap frequent itemset l, dicari semua subset dari l
- Untuk setiap subset tidak kosong s dari l, dihasilkan peraturan “s=>(l-s)” jika support_count(l) dibagi support_count(s)>=min_conf dimana min_conf adalah ambang minimum confidence.
Contoh
Misalkan data-data yang ada berbentuk seperti pada contoh sebelumnya, dan frequent itemset nya adalah l = {I1,I2,I5}. Apa saja association rule yang bisa didapat dari l? Subset dari l adalah {I1,I2}, {I1,I5}, {I2,I5},{I1},{I2}, dan {I5}. Berikut association rule nya dengan confidence:
I1ΛI2→I5 confidence = 2/4 = 50%
I1ΛI5→I2 confidence=2/2=100%
I2ΛI5→I1 confidence=2/2=100%
I1→I2ΛI5 confidence=2/6=33%
I2→I1ΛI5 confidence=2/7=29%
I5→I1ΛI2 confidence=2/2=100%
Jika ambang minimum confidence (yang ditentukan) adalah 70% maka hanya aturan kedua, ketiga, dan terakhir yang merupakan output, karena aturan-aturan ini yang kuat.
Post IV (22 Juli 2009)
Posting kali ini akan membahas definisi klasifikasi dan prediksi serta beberapa metode klasifikasi.
Basis data kaya akan informasi tersembunyi yang dapat digunakan untuk pengambilan keputusan yang tepat. Klasifikasi dan prediksi adalah dua bentuk analisa data yang dapat digunakan untuk membuat model yang menggambarkan kelas data yang penting untuk memprediksi kecenderungan data.
Apa itu klasifikasi? Apa itu prediksi?
Seorang petugas bank memerlukan analisa dari datanya untuk mengetahui mana peminjam yang “aman” dan mana yang “beresiko” untuk bank. Seorang manajer pemasaran dari sebuah toko elektronik memerlukan analisa data untuk membantu menebak apakah seorang pembeli dengan profil tertentu akan membeli komputer baru. Seorang peneliti medis ingin menganalisa data kanker untuk memprediksi mana dari 3 penanganan spesifik yang tepat pada seorang pasien. Pada tiap dari contoh tersebut adalah klasifikasi, dimana sebuah model dibuat untuk memprediksi sebuah label, seperti “aman” atau “beresiko” untuk data peminjam; “ya” atau “tidak” untuk data pemasaran. Kategori-kategori ini direpresentasikan dengan nilai diskrit, dimana urutan dari nilai tersebut tidak penting.
Misalnya seorang manajer pemasaran ingin memperkirakan berapa banyak seorang pembeli akan menghabiskan uangnya ketika masa obral di sebuah toko elektronik. Tugas analisa data ini adalah contoh prediksi numeric, dimana model dibuat untuk memprediksi sebuah nilai yang kontinu.
Bagaimana proses klasifikasi?
Klasifikasi data terdiri dari dua langkah proses: learning dan classification. Pada tahap learning, data dianalisa oleh algoritma klasifikasi. Sedangkan tahap classification, data test digunakan untuk memperkirakan akurasi dari aturan klasifikasi. Bila akurasinya dianggap bisa diterima, maka aturan tersebut dapat diaplikasikan pada klasifikasi tuple data baru.
Untuk lebih jelasnya dapat dilihat pada contoh dibawah ini:


Gb 4.1 (a)Tahap Learning (b)Tahap Classification
Bagaimana metode klasifikasi?
Metode klasifikasi ada banyak yaitu klasifikasi dengan induksi pohon keputusan, klasifikasi Bayesian, klasifikasi berdasarkan aturan, klasifikasi dengan backpropagation, dan masih ada yang lain. Metode yang paling terkenal adalah klasifikasi Bayesian karena mempunyai akurasi dan kecepatan yang tinggi ketika diterapkan pada basis data yang besar. Klasifikasi Bayesian ini juga banyak dibahas di tugas akhir mahasiswa tingkat atas yang mengambil topik data mining 😀
Karena banyaknya (dan rumitnya) semua metode tersebut, saya hanya akan mencoba membahas beberapa metode saja. Untuk lengkapnya silahkan melihat referensi di bawah khususnya buku karangan Han Jiawei.
Klasifikasi dengan induksi pohon keputusan
Sebuah pohon keputusan pada klasifikasi ini adalah struktur pohon yang seperti diagram alir, dimana setiap simpul internal (simpul non-daun) menunjukkan sebuah test pada sebuah atribut, setiap cabang merepresentasikan hasil dari test, dan setiap daun menyimpan label kelas.

Gb 4-2 Contoh pohon keputusan untuk menunjukkan apakah seorang pembeli akan membeli sebuah komputer.
Untuk membuat sebuah pohon keputusan terdapat suatu algoritma khusus. Ketika membuat pohon, attribute selection measures digunakan untuk memilih atribut yang terbaik untuk mempartisi tuple menjadi kelas yang berbeda. Ketika pohon telah terbentuk, banyak cabang yang merefleksikan data yang tidak sesuai. Tree pruning adalah teknik yang digunakan untuk mengidentifikasi dan menghapus cabang-cabang tersebut, dengan tujuan meningkatkan akurasi dari data yang tak pernah terlihat.
Klasifikasi ini cukup popular karena tidak membutuhkan pengetahuan domain data, sehingga cocok untuk mengeksplorasi dalam knowledge discovery. Pohon keputusan intuitif dan secara umum mudah dipahami oleh manusia. Tahap learning dan classification dalam klasifikasi ini sederhana dan cepat. Dan hal penting lainnya adalah tingkat akurasi yang cukup tinggi.
Klasifikasi berdasarkan-aturan
Model dari klasifikasi ini direpresentasikan dengan kumpulan IF-THEN. Aturan bisa didapat dari pohon keputusan maupun langsung dari data melalui algoritma sequential covering. Misalnya kita ingin membuat aturan klasifikasi dari pohon keputusan pada gambar 4-2, maka aturan yang terbentuk :
R1: IF age=youth AND student=no THEN buys_computer = no
R2: IF age=youth AND student=yes THEN buys_computer = yes
R3: IF age=middle_aged THEN buys_computer = yes
R4: IF age=senior AND credit_rating=excellent THEN buys_computer = yes
R5:IF age=senior AND credit_rating=fair THEN buys_computer=no
Sebuah disjungsi (OR) tidak muncul secara eksplisit karena aturan-aturan tersebut diambil secara langsung dari pohon, aturan tersebut mutually exclusive dan exhaustive. Mutually exclusive, berarti kita tidak bisa membuat aturan konflik karena tidak ada dua aturan yang sama pada tuple yang sama. (ada satu aturan tiap daun, dan semua tuple hanya bisa menuju ke satu daun). Exhaustive berarti urutan dari aturan tersebut tidak penting.
Post V (2 Agustus 2009)
Setelah membahas klasifikasi di postingan sebelumnya, saya akan membahas prediksi serta clustering, saya akan mulai dengan prediksi. Prediksi numerik adalah proses memprediksi nilai kontinu dari masukan yang diberikan. Sebagai contoh, kita ingin memprediksi gaji dari sarjana dalam 10 tahun mereka bekerja, atau angka penjualan potensial dari produk baru dengan harga sekian.
Jadi, bagaimana cara kita melakukan prediksi numeric?
Sejauh ini, pendekatan yang secara umum digunakan untuk prediksi numeric adalah regresi. Analisa regresi dapat digunakan untuk memodelkan hubungan antara satu atau lebih variabel independent atau predictor dan sebuah variabel dependent atau response. Biasanya nilai dari variabel predictor diketahui, variabel response lah yang ingin diprediksi. Analisa regresi adalah pilihan yang bagus dimana semua variabel predictor bernilai kontinu. Banyak permasalahan dapat diselesaikan dengan regresi linier, dan permasalahan yang lain juga bisa diselesaikan dengan mengubah variabelnya sehingga permasalahan nonlinier berubah menjadi linier.
Regresi liniernya sama dengan yang di matematika?
Secara konsep jawabannya adalah ya. Di sini saya akan membahas regresi garis lurus dimana ada sebuah variabel response, y, dan sebuah variabel predictor, x. Y kemudian dimodelkan sebagai fungsi linier dari x yaitu
y = w0 + w1x
Dimana w0 dan w1 merupakan koefisien regresi. Koefisien ini dapat dicari dengan metode least square, yang memperkirakan garis lurus yang paling cocok yang meminimasi kesalahan antara data yang sebenarnya dan garis perkiraan. Misalnya D adalah kumpulan nilai dari variabel predictor, x, dan nilai y yang sesuai dengan nilai x tersebut. Jadi D berisi data dalam bentuk (x1,y1), (x2,y2), ….
Koefisien regresinya dicari dengan persamaan,


Contoh:
Tabel dibawah menunjukkan kumpulan data dimana x adalah tahun lama bekerja dari seorang sarjana dan y adalah gajinya.

Dari data tersebut, dapat digambarkan sebagai titik-titik yang tersebar seperti yang ditunjukkan di atas. Dapat dilihat bahwa titik tersebut menyerupai bentuk garis lurus sehingga dapat diterka bahwa gaji berhubungan dengan lamanya pengalaman bekerja dengan persamaan y = w0 + w1x
Dengan data yang ada, nilai rata-rata x adalah 9.1 dan nilai rata-rata y adalah 55.4. Nilai tersebut disubstitusikan ke dalam persamaan dalam metode least square sehingga didapatkan w1 = 3.5 dan w0 = 23.6
Jadi persamaannya adalah y = 23.6 + 3.5x. Dengan persamaan ini, kita dapat memprediksi gaji seorang sarjana dengan 10 tahun pengalaman kerja adalah 58600.
Bayangkan misalnya kita diberikan kumpulan objek data untuk dianalisa yang berbeda dengan klasifikasi dimana label dari objek tidak diketahui. Hal seperti ini sering terjadi pada basis data yang besar, karena membuatkan label pada banyak objek merupakan proses yang mahal. Karena itu dibutuhkan proses yang dinamakan clustering.
Apa itu clustering?
Clustering adalah proses mengelompokkan data ke dalam kelas atau cluster, jadi objek-objek di dalam cluster yang sama mempunyai persamaan yang besar tetapi sangat berbeda dibandingkan objek pada cluster yang lain. Perbedaan yang dimaksud dilihat berdasarkan nilai atribut yang menggambarkan objek. Walaupun klasifikasi adalah metode efektif untuk membedakan grup atau kelas dari objek, tetapi seringkali memberi label dari kumpulan besar data merupakan proses yang mahal. Sehingga lebih efektif bila proses tersebut dibalik : pertama mempartisi kumpulan data menjadi kelompok berdasarkan kesamaan data (menggunakan clustering) kemudian memberi label kepada sejumlah grup yang relatif kecil.
Apa saja metode clustering?
Lagi-lagi karena rumitnya tiap metode clustering, saya hanya membahas garis besar tiap metode tersebut 😛
- Metode partisi
Diberikan sebuah basis data dengan n objek, metode partisi akan membangun k partisi dari data, dimana setiap partisi mewakilkan sebuah cluster dan k<=n. Dan setiap kelompok tersebut memenuhi aturan : (1) setiap kelompok harus terdapat paling sedikit satu objek, dan (2) setiap objek harus masuk dalam tepat satu kelompok.
- Metode Hirarki
Seperti namanya metode ini menciptakan dekomposisi hirarki dari kumpulan objek yang diberikan. Metode hirarki ini dapat digolongkan baik agglomerative atau divisive berdasarkan bagaimana dekomposisi hirarki tersebut dibuat. Pendekatan agglomerative, yang juga disebut pendekatan bottom-up, mulai dengan tiap objek membentuk grup terpisah. Kemudian berturut-turut menggabungkan grup yang dekat satu dengan yang lain, sampai semua grup tergabung menjadi satu (metode yang mengingatkan saya pada prosedur merge dalam merge sort :D). Pendekatan divisive yang juga disebut pendekatan top-down merupakan kebalikannya, mulai dari semua objek dalam cluster yang sama. Pada setiap iterasi, sebuah cluster dibagi menjadi cluster yang lebih kecil sampai setiap objek pada satu cluster.
- Metode berdasarkan-densitas
Idenya adalah melanjutkan mengembangkan cluster selama densitas (jumlah objek) pada cluster tetangga melebihi batas tertentu. Maksudnya, setiap poin data pada cluster tertentu, cluster sekitarnya pada radius tertentu harus mempunyai paling sedikit sejumlah poin yang memenuhi batas minimum.
- Metode berdasarkan-kotak
Metode ini membuat ruang objek menjadi sel dengan jumlah tertentu yang membentuk struktur kotak. Semua operasi clustering dilakukan pada struktur kotak. Keuntungan dari pendekatan ini adalah kecepatan proses yang tidak bergantung pada jumlah objek dan hanya bergantung pada jumlah sel pada tiap dimensi.
- Metode berdasarkan-model
Metode berdasarkan-model menghipotesa sebuah model untuk tiap cluster dan mencari model yang paling tepat pada data yang diberikan. Algoritmanya akan menempatkan cluster dengan membuat fungsi densitas yang berfungsi menentukan jumlah cluster berdasarkan statistik.
Pilihan algoritma clustering tergantung tipe data yang ada dan aplikasi yang diterapkan. Jika analisa cluster digunakan sebagai alat eksplorasi, sebaiknya mencoba beberapa algoritma pada data yang sama.
Oke, setelah clustering berikutnya ada apa lagi?
Sayang sekali tapi selesailah konsep dan teknik dasar dari data mining (dari pencarian asosiasi, pencarian kelompok objek, klasifikasi, prediksi dan sampai pada clustering). Tetapi teknik yang saya bahas hanya untuk struktur data yang sederhana seperti data dalam basis data relasional, transactional, dan data warehouse. Dewasa ini data tumbuh ke dalam bentuk yang kompleks (semi-terstruktur dan tidak terstruktur, spatial dan temporal, hypertext dan multimedia) karena pertumbuhan yang cepat dari koleksi data, teknologi sistem basis data yang kompleks, dan World Wide Web. Karena itu, tugas data mining dituntut untuk semakin berkembang untuk menggali data yang semakin kompleks. Dengan demikian, data mining sampai saat ini masih terus berkembang sehingga sangat menarik untuk dipelajari.
Daftar Referensi
Cheng, J. Bell, D. A., Liu, W. 2001. Learning Bayesian Network from Data : An Information-Theory Based Approach. University of Ulster.
Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. 1996. From Data Mining to Knowledge Discovery. AAAI/MIT Press, Cambridge, Mass.
Fayyad, U., Piatetsky-Shapiro, G., Smyth, P. 1996. The KDD Process for Extracting Useful Knowledge from Volumes of Data. Communication of the ACM.
Han, Jiawei; Kamber, Micheline. 2006. Data Mining: Concepts and Techniques. Morgan Kaufmann Publisher.
Sophia, Aya. 2005. Algoritma PC Sebagai Alternatif Pendekatan Analisis Dependensi Untuk Konstruksi Struktur Bayesian Network Dalam Data Mining.
Two Crows. 1999. Introduction to Data Mining and Knowledge Discovery. Two Crows Publisher.
Deductive Database for BasDat-ers
June 10, 2009
EDISI I oleh Mochamad Ikrar Pradana / 13507063
10 Juni 2009
Apa itu Deductive Database ??
Untuk yang penasaran :), Deductive Database merupakan area perpotongan antara basis data, logika, dan intelegensia buatan. Sistem Deductive Database sendiri biasa dipanggil juga dengan sebutan Logic Databases. Kenapa begitu ?? Hal ini disebabkan oleh kapabilitas mekanisme dari sistem ini untuk memberikan pengetahuan baru tentang suatu data yang tersimpan, dengan menambahkan suatu ‘pola hubungan’ antardata — yang disebut dengan istilah rules. Nah, karena kelebihan di poin ini…
Sistem Deductive Database didefinisikan sebagai sebuah sistem basis data yang memiliki kemampuan untuk mendefinisikan rules turunan (deduktif) yang dapat memberi kesimpulan berupa suatu informasi tambahan, mengenai fakta-fakta yang tersimpan di dalamnya.
Hal lain tentang sistem basis data ini adalah bahwa sistem ini merupakan salah satu ekstensi dari sistem basis data relasional. Namun, tidak seperti kebanyakan ekstensi sistem relasional lainnya, sistem ini memiliki sifat deklaratif. Sistem yang seperti apakah itu ?? Sistem yang deklaratif adalah sistem yang memfasilitasi penggunanya untuk melakukan query ataupun update dengan menjabarkan Apa yang ingin dihasilkan oleh sistem — bukan Bagaimana sistem harus beroperasi.
Jadi, teknologi Deductive Database memiliki kelebihan di beberapa poin..
1. Sifat sistem yang deklaratif
Pada sistem relasional yang terdahulu, banyak timbul permasalahan pada optimisasi peng-kode-an query. Dengan kemudahan yang diberikan oleh sistem, operasi sistem hampir bisa dipastikan sebagai operasi yang paling efisien dan efektif untuk memberikan hasil yang diinginkan.
2. Kemampuan sistem untuk menyajikan semantik data yang non-monotonic
Kesimpulan yang tidak monoton adalah kesimpulan yang tidak bisa diperoleh dari fungsi logika klasik. Sistem ini mampu untuk memberikan definisi yang lebih dari logical statements yang tersimpan di dalamnya, kepada programmer.
———————————————————————————————————–
EDISI II oleh Mochamad Ikrar Pradana / 13507063
25 Juni 2009
Konsep apakah yang perlu dipahami terkait dengan Deductive Database ?? part 1
Oke.. sekarang sudah jelas kan, kira-kira dalam kasus seperti apa saja sistem basis data deduktif ini pas untuk digunakan. Sebelum mulai menggunakan aplikasi dari sistem ini, terdapat beberapa konsep yang perlu dipahami terlebih dahulu…
Konsep Prolog
Prolog adalah satu bentuk logic programming yang berkaitan dengan intelegensia buatan dan bahasa komputasional. Penggunaan prolog inilah yang membuat Deductive Database sangat berkaitan erat dengan pemrograman berbasis logika, sampai-sampai Deductive Database sendiri bahkan bisa disebut sebagai suatu bentuk adaptasi dari pemrograman prolog di bidang basis data. Terdapat beberapa hal yang perlu diperhatikan terkait dengan hal ini :
1. Strategi evaluasi pada penggunaan prolog adalah depth first
Hal ini menyebabkan adanya kemungkinan untuk didapatkan hasil berupa infinite loops. Oleh sebab itu, sebaiknya untuk volume data yang besar lebih diutamakan kesempurnaan dan kejelasan terminasi dari metode evaluasi, dibanding argumen-argumen operasional.
2. Dalam pengaplikasian basis data, pada umumnya jumlah data yang diolah sangat besar sehingga mayoritasnya tersimpan di secondary storage.
Maka itu, efisiensi akses ke data yang bersangkutan sangatlah krusial dalam menentukan kebagusan performansi dari sistem.
Tipe data tunggal dari sebuah prolog adalah term. Term dapat berupa atoms, numbers, variables atau compound terms.
Atom adalah nama yang umum tanpa satu arti yang spesifik. Atom terdiri dari satu sequence karakter yang di-parse sebagai satu unit tunggal tanpa sintax tertentu, seperti ; kucing, [ ], jalan_raya, ‘Kurap’, ‘atom aja’, dan lain sebagainya.
Numbers dapat berbentuk integer, float, ataupun bilangan rasional lainnya.
Variables terdiri dari satu set huruf, atau beberapa kata yang digabungkan dengan ‘_’ (underscore), dimulai dengan huruf kapital.
Compound term terdiri dari sebuah atom yang disebut functor dan beberapa term yang disebut argumen . Compound terms biasa dituliskan dengan urutan; functor, diikuti sebuah list argumen dipisahkan dengan tanda koma di dalam tanda kurung. Jumlah dari argumen disebut sebagai arity dari term. Hal ini membuat sebuah atom disebut sebagai term dengan arity sejumlah nol.
Contoh compound term:
pacaran(andi, dona) –> arity = 2
‘Punya_Mobil'(gugun, [‘Mercy’, ‘BMW’, ‘Avanza’]) –> arity = 2
tambah(x, y, hasil) –> arity = 3 … diketahui x dan y
Begitu saudara-saudara :)… Jadi terlihat sekarang bahwa prolog di dalam Deductive Database menyebabkan eratnya konsep pemrograman logika di sistem basis data ini.
———————————————————————————————————–
EDISI III oleh Mochamad Ikrar Pradana / 13507063
11 Juli 2009
Konsep apakah yang perlu dipahami terkait dengan Deductive Database ?? part 2
Di edisi sebelumnya sudah dibahas mengenai Prolog. Nah, kira-kira prolog ini dikembangkan ke arah mana ya di dalam Deductive Database ??
Konsep Facts & Rules
Dalam notasi dan penggunaan Deductive Database, terdapat dua hal yang menjadi bahan ‘mainan’ nih; yaitu facts & rules..
- Facts atau Data diwakili oleh predikat dan disertai dengan konstanta argumen
contoh : adik (Popi, Hani) —-> berarti Popi adalah adik dari Hani.. ‘ adik ‘ disini merupakan predikat yang menghubungkan Popi dengan Hani.
- Rules atau Program digunakan untuk mendefinisikan relasi virtual berdasarkan suatu spesifikasi tertentu. Biasanya dituliskan dalam notasi Prolog seperti (ex. p :- q1, …, qn).
p disebut Head yang merupakan konklusi dari program. Head akan bernilai true jika setiap predikat di bagian kanannya bersifat true; q1, …, qn disebut Body atau subgoal. Tanda koma antar variabel bisa dibaca sebagai hubungan ‘and’; tanda :- memiliki arti seperti ‘ if ‘.
contoh : bos (Dodi, Asep) :- memerintah (Dodi, Asep) —-> Dodi adalah bos dari Asep, jika Dodi memerintah Asep
Contoh …
Facts :
guru (Budi, Tono)
guru (Tono, Santi), ayah(Papa, Ina)
Rules :
guru (Budi, Tono) :- mengajar (Budi, Tono)
guru (Tono, Santi) :- murid (Santi, Tono)
guru (Budi, Santi) :- guru (Budi, Tono), guru (Tono, Santi)
ayah (Papa, Ina) :- anak (Ina, Papa), pria (Papa)
Jelas kan 🙂 ? Jadi notasi di dalam Deductive Database memiliki bentuk yang persis seperti pemrograman logika, yaitu dengan Prolog.
———————————————————————————————————–
EDISI IV oleh Mochamad Ikrar Pradana / 13507063
25 Juli 2009
Interpretasi & Meaning dari Query
Oke… Setelah memengerti penulisan Query dalam Deductive Database (Prolog), selanjutnya perlu diketahui dulu bagaimana cara kita menginterpretasikan maknanya.
1. Bila argumen terdiri satu atau lebih variabel, query akan mengembalikan ‘nilai’ dari variabel
2. Bila argumen terdiri dari konstanta saja, query akan mengembalikan nilai True atau False
contoh Query :
ayah(Papa, Ina)?
Seperti yang sudah beberapa kali disebutkan, Deductive Database akan selalu mengenai Facts & Rules. Nah terkait dengan itu, terdapat beberapa alternatif cara mendefinisikan makna dari Rules..
1. Proof-theoretic Interpretation
Dengan cara ini kita bermaksud membuktikan suatu fakta dari fakta2 lain di dalam database, menggunakan rules. Hal ini dilakukan dengan membaca rule dengan arah maju; mengartikan bagian kiri(konklusi) dari fakta di bagian kanan(argumen).
contoh:
pilot(Joko) :- menerbangkan(Joko, Pesawat)
dibaca –> Joko adalah seorang Pilot, karena Joko menerbangkan Pesawat
2. Model-theoretic Interpretation
Dengan cara ini, kita melihat rules sebagai model yang memberikan nilai ‘true’ atau ‘false’ kepada tiap kemungkinan instance dari predikat rules tadi.
3. Computational Definition of Meaning
Ini dilakukan dengan menyusun sebuah algoritma yang mengeksekusi logical rules, untuk menentukan kebenaran dari fakta2 lainnya.
Oke, sampai sini dulu untuk edisi kali ini. Semoga bermanfaat… 🙂
———————————————————————————————————–
EDISI V oleh Mochamad Ikrar Pradana / 13507063
10 Agustus 2009
KESIMPULAN
/*
Sebelumnya saya meminta maaf dulu atas keterlambatan saya posting. Hal ini dikarenakan deadline posting yang ternyata jatuh pada minggu terakhir magang saya di Balikpapan, ketika saya tengah penuh mempersiapkan laporan dan interview akhir. Untuk itu, saya berterimakasih apabila saya diijinkan untuk mem-post sekarang, setelah saya kembali berada di pulau jawa. Atas maklum kakak2, saya sangat berterimakasih..
*/
Akhirnya kita sampai juga di penghujung eksplorasi. Setelah mempelajari banyak mengenai Deductive Database, bisa di-review kembali hal-hal yang terkait dengan sistem basis data ini…
- Deductive Database disebut juga Logic Databases, karena mampu memberikan informasi turunan mengenai suatu fakta
- Deductive Database bersifat deklaratif
- Deductive Database menyajikan data yang tidak monotonik
- Deductive Database menggunakan konsep Prolog dalam implementasinya
- Deductive Database dapat diinterpretasikan melalui lebih dari satu cara pemahaman
(serius mode on) Deductive database telah mampu menjadi interface antara permasalahan teoritis dan praktikal. Untuk menjadi ekstensi basis data relasional dengan tetap memiliki gaya pemrograman yang deklaratif, Deductive Database menggunakan bahasa berbasiskan rules yang mampu mengekspresikan aplikasi yang komplit. Dengan ini, diyakini bahwa Deductive Database akan bisa meningkatkan kemampuan sistem basis data untuk menjadi solusi permasalahan di masa depan, secara substansial. Beberapa hal yang dapat dilakukan oleh sistem basis data ini adalah kemampuan untuk mengekspresikan query yang kompleks untuk mengidentifikasikan pola pengembangan dalam database yang besar, dan berurusan dengan database heterogen yang terdistribusi.
(serius mode off) Jadi cukup sudah pengetahuan mendasar yang bisa dipaparkan disini mengenai Deductive Database. Semoga jadi bermanfaat, dan dapat menumbuhkan minat teman-teman yang membaca tentang kelimuan Basis Data.
Sampai JUMPA !!! 🙂
============================================================ THE END….
— for better Lab BasDat —
Daftar Pustaka :
http://en.wikipedia.org/wiki/Deductive_database. Akses : 10 Juni 2009
http://en.wikipedia.org/wiki/Non-monotonic_logic. Akses : 10 Juni 2009
http://en.wikipedia.org/wiki/Prolog. Akses : 25 Juni 2009
http://en.wikipedia.org/wiki/Horn_clause. Akses : 25 Juni 2009
http://en.wikipedia.org/wiki/Logic_programming. Akses : 11 Juli 2009
http://kti.mff.cuni.cz/~bartak/prolog/first_steps.html. Akses : 25 Juni 2009
Slide Kuliah IF5011. 2003. Deductive Databases. Teknik Informatika ITB
Ullman, Jeffrey D, Zaniolo, Carlo. 1990. Deductive Databases: Achievements and Future Directions. Stanford University
Ullman, Jeffrey D, and friends. 1993. A Survey of Research on Deductive Database Systems. Stanford University
Data Warehouse
June 9, 2009
oleh Samsu Sempena / 13507088
Post #1 (dirilis : 9 Juni 2009) — pengertian, sejarah ,arsitektur
Post #2 (dirilis : 23 Juni 2009) — ilustrasi, metode penyimpanan, metode perancangan
Post #3 (dirilis : 2 Juli 2009) — sifat data warehouse,perbandingan dengan OLTP, perbandingan dengan sistem operasional
Post #4 (dirilis : 24 Juli 2009) — komponen dan skema data warehouse
Post #5 (dirilis : 7 Agustus 2009) — Keuntungan,kelebihan,dan aplikasi data warehouse
Post #1 (9 Juni 2009)
Dalam postingan pertama untuk tugas eksplorasi mengenai data warehouse akan dibahas mengenai data warehouse : apa itu data warehouse, sejarahnya, dan arsitektur dasarnya.
Data warehouse adalah sebuah repositori atau tempat penyimpanan data secara elektronis yang dimiliki sebuah organisasi. Data warehouse juga dirancang untuk dapat memfasilitasi pembuatan laporan dan analisis.
Sekalipun demikian, data warehouse tidak hanya berfokus pada penyimpanan data, tapi sebuah sistem data warehouse memiliki komponen-komponen esensial seperti menerima (retrieve), menganalisis (analyze) data, mengekstrak (extract), mengubah (transform), meload data, dan juga mengatur data dictionary. Sehingga definisi lebih luas dari data warehouse mencakup kakas kecerdasan bisnis (business intelligence tools), kakas untuk mengekstrak (tools to ekstrak), mengubah (transform), dan menerima data (load) ke penyimpanan (repository), serta mengelola dan menerima metadata.
| Tahun | Peristiwa |
| 1960 | General Mills dan Dartmouth College dalam riset bersama mengembangkan istilah dimensi dan fakta |
| 1970 | ACNielsen dan IRI menyediakan data dimensional untuk pembelian secara eceran |
| 1983 | Teradata memperkenalkan Database Management System (DBMS) yang dirancang khusus untuk dukungan pengambilan keputusan |
| 1988 | Barry Devlin dan Paul Murphy mempublikasikan artikel “An architecture for a business and information systems” di jurnal IBM System saat mereka memperkenalkan istilah “business data warehouse” |
| 1990 | Red Brick Systems memperkenalkan Red Brick Warehouse, sebuah DBMS khusus untuk data warehouse |
| 1991 | Prism Solutions memperkenalkan Prism Warehouse Manager, sebuah perangkat lunak untuk mengembangkan data warehouse |
| 1991 | Bill Inmon mempublikasikan buku “Building the Data Warehouse” |
| 1995 | Dibangunnya Institut Data Warehousing |
| 1996 | Ralph Kimball mempublikasikan buku “The Data Warehouse Toolkit” |
| 1997 | Oracle 8, dengan support untuk query bintang (star queries) dirilis |
Arsitektur Data Warehouse
Arsitektur dalam konteks organisasi data warehouse adalah konsep bagaimana data warehouse dibangun. Tidak ada arsitektur yang benar maupun salah, melainkan berbagai arsitektur ada untuk mendukung berbagai situasi dan kondisi. Arsitektur yang baik akan berimbas pada pembangunan, pemeliharaan, dan penggunaan dari data warehouse.
Namun, pada umumnya arsitektur data warehouse akan memiliki lapisan-lapisan berikut :
- Operational database layer (lapisan basis data operasional)
- Sumber data untuk data warehouse
- Data access layer (lapisan akses data)
- Antarmuka antara lapisan operasional dan akses informasi
- Kakas untuk mengekstrak, mengubah, dan meload data
- Metadata layer(lapisan metadata)
- Direktori data
- Umumnya lebih detail daripada direktori data sistem
- Ada kamus untuk keseluruhan warehouse dan terkadang ada kamus untuk data yang dapat diakses oleh reporting khusus dan kakas untuk analisis
- Informational access layer (lapisan akses informasi)
- Akses data dan juga kakas untuk reporting,analisis
- Kakas intelejensia bisnis (Business Intelligence) termasuk ke lapisan ini
post #2 (23 Juni 2009)
Umumnya data warehouse diperlukan oleh perusahaan besar yang memiliki banyak cabang dan memiliki sejumlah besar data atau struktur perusahaan yang kompleks. Mengapa demikian?

decision maker
Bayangkanlah sebuah perusahaan jual-beli yang memiliki banyak cabang, atau perusahaan asuransi yang memiliki data dari ribuan cabang lokal. Tentunya data-data yang dimiliki tersebar di banyak lokasi yang berbeda, sistem operasi yang berbeda, atau disimpan dengan skema yang berbeda. Sebagai contoh, data produksi dan data keluhan pelanggan disimpan di sistem database yang berbeda. Lalu akan diambil suatu keputusan untuk perusahaan tersebut oleh pembuat keputusan (decision maker). Pembuat keputusan itu tentunya membutuhkan akses ke semua sumber data yang ada. Namun dengan melakukan query ke setiap sumber individual tentunya tidak praktis dan tidak efisien. Atau sumber data mungkin hanya menyimpan data terkini, sementara pembuat keputusan perlu mengakses data-data terdahulu pada perusahaan itu. Misalnya saja informasi mengenai pola penjualan yang berubah dari tahun-tahun lalu merupakan pertimbangan penting dalam mengambil keputusan. Nah, data warehouse menyediakan solusi bagi masalah ini.
Bagaimana prinsip penyimpanan data dalam data warehouse?
Ada 2 pendekatan utama untuk menyimpan data dalam data warehouse :
1. Pendekatan dimensional
Pada pendekatan ini, data transaksi dipartisi menjadi fakta (umumnya data transaksi yang numeric) atau dimensi (referensi ke informasi dari fakta)
Sebagai contoh:
Data penjualan dapat dipisahkan menjadi fakta seperti jumlah produk yang dipesan dan harga yang dibayarkan untuk setiap produk. Dan menjadi dimensi, seperti tanggal pemesanan, nama pembeli, nomor produk, petugas yang bertanggung jawab atas pemesanan tersebut, dll.
(+) data warehouse akan lebih mudah untuk digunakan dan dimengerti oleh pengguna
(+) penerimaan data dari data warehouse dilakukan dengan sangat cepat
(-) untuk mempertahankan integritas dari fakta dan dimensi, meload data warehouse dari sistem operasi yang berbeda-beda menjadi kompleks
(-)akan sulit untuk mengubah struktur data warehouse jika organisasi tersebut perubahan dalam cara melakukan bisnisnya
2. Pendekatan normalisasi
Pada pendekatan ini, data dalam data warehouse disimpan berdasarkan aturan normalisasi data. Tabel dikelompokkan berdasarkan kategori (seperti pelanggan, produk, keuangan,dll).
(+)Mudah untuk menambahkan informasi ke database
(-)karena banyaknya table yang terlibat maka akan sulit bagi pengguna untuk menggabungkan data dari sumber yang berbeda menjadi informasi atau untuk mengakses informasi tanpa benar-benar mengerti isi dari sumber data dan struktur data dari data warehouse.
Sekalipun demikian, kedua pendekatan ini tidaklah benar-benar terpisah satu sama lain. Pendekatan dimensional juga dapat melibatkan pendekatan normalisasi sampai pada tingkat tertentu.
Metode perancangan data warehouse
1. Perancangan bottom-up
Ralph Kimball,seorang pakar dalam data warehousing adalah pendukung dari pendekatan perancangan data warehouse yang disebut bottom-up. Disebut bottom-up karena pertama-tama data pada cabang/pasar dibuat lebih dulu untuk menyediakan kapabilitas laporan dan analisis untuk proses bisnis tertentu. Data cabang ini dapat dikombinasikan untuk membuat sebuah data warehouse.
(+) nilai bisnis dapat dikembalikan secepat data cabang pertama dibuat. (kecepatan)
(-) sulit untuk memastikan kekonsistenan dimensi dari kesemua data cabang.
2. Perancangan top-down
Bill Inmon seorang penulis pertama mengenai data warehouse mendefinisikan data warehouse sebagai repository pusat untuk keseluruhan enterprise/perusahaan. Inmon merupakan pendukung dari pendekatan perancangan data warehouse yang disebut top-down, dimana data warehouse dirancang menggunakan data model enterprise yang telah dinormalisasi.
(+) Metode perancangan top-down menghasilkan dimensional view yang konsisten dari semua data yang berasal dari data cabang karena semua data cabang diload dari repository terpusat.
(+)Perancangan top-down telah membuktikan dirinya sanggup menghadapi perubahan pada bisnis, membuat data dimensional cabang yang baru menjadi tugas yang mudah.
(-) merepresentasikan projek yang sangat besar dengan cakupan yang luas, sehingga membutuhkan biaya yang besar untuk mengimplementasikan data warehouse dengan metode top-down.
(-) durasi waktu dari dimulainya projek sampai pengguna dapat merasakan manfaat warehouse cukup terasa
(-) metode top-down dapat menjadi tidak fleksible terhadap perubahan kebutuhan di tahap implementasi
3. Perancangan hibrid
Seiring berjalannya waktu ternyata metode bottom-up dan top-down pada perancangan data warehouse memiliki keuntungan dan kerugian / resiko. Maka metode hybrid mencoba untuk mengambil keunggulan kecepatan dari metode bottom-up dan kekonsistenan data enterprise dari metode top-down.

data warehouse architecture
post #3 (2 Juli 2009)
Sifat-sifat dari data warehouse
— Berorientasi pada suatu persoalan (subject oriented)
Data warehouse dirancang untuk membantu kita dalam menganalisis data. Misalnya, kita ingin mempelajari mengenai data penjualan suatu perusahaan. Untuk melakukan ini, kita dapat membangun data warehouse yang terkonsentrasi pada penjualan. Dengan data warehouse ini, kita dapat menjawab pertanyaan seperti : “siapakah pembeli terbaik dari perusahaan ini tahun lalu?”
— Terintegrasi (integrated)
Data warehouse membutuhkan data dari beberapa sumber terpisah untuk disimpan ke suatu format khusus. Hal ini berarti konflik pemberian nama atau masalah dalam penggunaan unit pengukuran yang berbeda seperti “inch” dan “cm” harus diselesaikan.
— Bersifat tetap (non volatile)
Hal ini berarti data tidak akan pernah berubah atau diubah sekali masuk ke data warehouse. Hal ini jelas mengingat tujuan dari data warehouse adalah untuk menganalisis apa yang terjadi.
— Bervariasi terhadap waktu (time variant)
Kebanyakan analisis bisnis membutuhkan tren analisis. Karenanya analis membutuhkan data yang besar jumlahnya dengan melihat perubahan tren yang terjadi terhadap waktu. Hal ini menjadi kontras dibandingkan dengan sistem OLTP (Online Transaction Processing Systems).
Data warehouse dibandingkan dengan OLTP System

| Data Warehouse | Online Transaction Processing Systems | |
| Workload | Didesain untuk menangani query dalam jumlah besar | Hanya mendukung operasi tertentu yang telah ditentukan sebelumnya |
| Data modification | Data warehouse diperbaharui dalam jadwal tertentu melalui proses ETL menggunakan teknik modifikasi data bulk (dalam jumlah besar). Pengguna tidak mengupdate data warehouse secara langsung kecuali menggunakan peralatan seperti data mining. | User melakukan proses update data secara langsung dan database selalu dalam kondisi terupdate (paling baru) |
| Schema design | Umumnya tidak dinormalisasi atau sebagian ternormalisasi (seperti star schema) untuk mengoptimasi query dan performansi analitis |
Menggunakan skema yang telah inormalisasi untuk mengoptimasi proses insert/update/delete dan juga memastikan integritas data |
| Typical Operation | Menjalankan query yang memproses banyak record sekaligus, contohnya : total penjualan semua customer pada akhir bulan |
Tidak semua record, misalnya mencari data order untuk pelanggan tertentu |
| Historical data | Menyimpan data selama jangka bulan bahkan tahun. Hal ini bertujuan untuk mendukung analisis historical dan juga laporan |
Hanya menyimpan data minggu-minggu atau bulan terakhir. Hanya menyimpan data yang dibutuhkan untuk transaksi saat ini. |
Sistem operasional dibandingkan dengan data warehouse
Sistem operasional optimal dalam menjamin integritas data dan kecepatan untuk menyimpan transaksi bisnis yang terjadi melalui normalisasi database dan model entity-relationship. Pada umumnya, perancang sistem operasinal mengikuti aturan normalisasi Codd. Database relational efisien untuk mengelola relasi antara tabel dan database akan memiliki performansi tinggi untuk proses insert maupun update karena hanya sejumlah kecil data dalam tabel yang dipengaruhi.
Sementara data warehouse optimal dalam kecepatan untuk menerima data. Secara berkesinambungan, data dalam data warehouse didenormalisasi dengan model berbasis dimensional. Selain itu, untuk mempercepat penerimaan data, data warehouse juga sering disimpan berkali-kali di bentuk lengkapnya dan juga di bentuk ringkasnya yang disebut aggregasi. Data dari data warehouse dikumpulkan dari sistem operasional dan tetap disimpan di data warehouse sekalipun data tersebut telah dibuang dari sistem operasional
Evolusi dalam perusahaan yang menggunakan data warehouse
Pada umumnya organisasi atau katakanlah suatu perusahaan memulai dengan data warehouse yang relatif simple. Seiring berlalunya waktu, kebutuhan akan data warehouse yang lebih canggi semakin meningkat. Pada umumnya tingkat-tingkat kebutuhan akan data warehouse dapat dibedakan sebagai berikut :
— Database operasional offline
Pada tahap ni secara sederhana data warehouse dibangun dengan menduplikasi data dari sistem operasional ke server lain sehingga saat dibutuhkannya proses terhadap data-data tersebut misalnya saja pembuatan laporan tidak akan mengimbas pada performansi sistem operasional.
— Data warehouse offline
Pada tahap ini data warehouse diperbaharui dari data di sistem operasional ke suatu bentuk umum dan data dari data warehouse disimpan dengan struktur data yang dirancang untuk memfasilitasi proses pembuatan laporan.
— Data warehouse realtime
Pada tahap ini, data warehouse diperbaharui setiap sistem operasional melalukan transaksi bisnis
— Data warehouse terintegrasi
Sama seperti pada data warehouse realtime, namun setiap kali terjadi proses update ke data warehouse, maka data warehouse akan menghasilkan sebuah transaksi yang dikembalikan ke sistem operasional.
Post #4 (24 Juli 2009)
Komponen dari sebuah data warehouse
Kapan dan bagaimana mendapatkan data
Dalam source-driven architecture, maka sumber data mengirimkan informasi baru, baik secara kontinu maupun periodik (misalnya setiap malam)
Dalam destination-driven architecture, maka data warehouse secara periodik mengirimkan permintaan akan data yang baru ke sumber data
Skema yang digunakan
Sumber data yang dibuat masing-masing kemungkinan memiliki skema yang berbeda. Bahkan, mereka mungkin juga menggunakan data model yang berberda. Tugas dari data warehouse adalah untuk melakukan pengintegrasian skema dan mengubah data yang diterima menjadi skema terintegrasi sebelum disimpan. Sebagai hasilnya, data yang disimpan di data warehouse tidak hanya sekedar salinan dari sumber data. Melainkan telah diintegrasikan dengan data-data dari sumber lain.
Pembersihan data (data cleansing)
Tugas untuk memperbaiki dan mempersiapkan data disebut data cleansing. Sumber data sering mengirimkan data dengan banyak ketidakkonsistenan minor yang dapat diperbaiki. Misalnya, nama sering kali salah eja dan alamat berupa jalan/area/kota juga salah eja, atau kode pos salah. Hal ini dapat diperbaiki dengan merelasikannya dengan basis data dari nama jalan dan kode pos dari setiap kota. Daftar alamat yang digabungkan dari beberapa sumber mungkin terduplikasi sehingga perlu dieliminasi dengan operasi merge-purge (operasi natural-join).
Bagaimana menyebarkan update?
Update dalam sebuah relasi dari sumber data harus disebarkan juga ke data warehouse. Jika relasi pada data warehouse benar-benar serupa dengan yang di sumber data maka penyebarannya mudah. Namun jika tidak, maka permasalahan untuk memastikan update ini disebut masalah view-maintenance.
Data apa yang dapat digabungkan(aggregasi)
Data mentah yang dihasilkan dari proses transaksi mungkin terlalu besar untuk disimpan secara online. Namun kita dapat menjawab banyak query dengan mengelola hanya ringkasa data yang didapatkan dengan melakukan agregasi pada suatu relasi daripada mengelola seluruh relasi Sebagai contoh : daripada menyimpan data penjualan pakaian setiap hari, kita dapat menyimpan total penjualan suatu pakaian berdasarkan nama dan kategori.
Skema
Data warehouse memiliki skema yang dirancang untuk analisis data dan pada umumnya menggunakan perangkat OLAP(Online Analitical Processing). Data umumnya berupa data multidimensi (terdiri dari atribut dimensi dan pengukur) dan tabel yang menyimpan data ini disebut tabel fakta (fact table) dan biasanya sangat besar. Tabel yang menyimpan data penjualan suatu perusahaan ritel, dengan satu tuple untuk setiap barang yang terjual merupakan contoh dari tabel fakta. Atribut dimensi dari tabel penjualan akan mencakup barang apa itu (misalnya dengan barcode), tanggal dijualnya, lokasi toko dijualnya, pelanggan mana yang membelinya, dst. Atribut pengukur misalnya jumlah dan harga barang. Untuk meminimalkan kebutuhan penyimpanan, atribut dimensi seringkali disingkat dengan foreign key ke tabel lain yang disebut tabel dimensi (dimension tables).
Sebagai contoh,sebuah tabel fakta penjualan akan memiliki atribut item-id, store-id, customer-id, dan tanggal, serta atribut pengukur jumlah dan harga. Atribut store-id adalah foreign key ke sebuah tabel dimensi store yang memiliki atribut lain seperti lokasi toko (kota, wilayah, negara). Atribut item-id juga merupakan foreign key ke tabel dimensi item-info yang memiliki atribut seperti warna dan ukuran. Untuk lebih jelasnya dapat diamati dari bagan berikut :

Post #5
7 Agustus 2009
Keuntungan menggunakan data warehouse
- Data warehouse menyediakan model data yang umum untuk semua data tidak tergantung sumber datanya. Hal ini mempermudah pembuatan laporan dan analisis informasi dibandingkan jika diperlukan banyak model data untuk menerima informasi seperti faktur penjualan, kuitansi pemesanan, tagihan-tagihan lainnya.
- Saat meload data ke dalam datawarehouse, ketidakkonsistenan akan teridentifikasi dan diperbaiki. Hal ini akan mendukung juga dalam proses pembuatan laporan dan analisis.
- Informasi yang disimpan dalam data warehouse dibawah kontrol dari pengguna data warehouse, sehingga sekalipun sumber data dibersihkan pada suatu waktu, informasi itu akan tetap tersimpan dengan aman di data warehouse.
- Karena data warehouse terpisah dari sistem operasional, maka data warehouse dapat menerima data tanpa memperlambat kerja kerja sistem operasional
- Data warehouse menyediakan fasilitas yang mendukung pengambilan keputusan seperti laporan berdasarkan tren (misalnya : barang yang paling banyak terjual di suatu area dalam 2 tahun terakhir), laporan perkecualian, dan laporan yang menampilkan pencapaian di lapangan yang sesungguhnya dibandingan dengan gol yang telah ditetapkan.
Kerugian menggunakan data warehouse
- Data warehouse bukan merupakan lingkungan yang optimal untuk data yang tidak terstruktur
- Data perlu untuk diekstrak, diubah, dan diload ke data warehouse, sehinggan terdapat delay (tenggat waktu) di mana data yang dimasukkan ke dalam data warehouse belum terdeteksi.
- Semakin lama masa hidupnya, maka data warehouse dapat menyebabkan biaya yang besar. Data warehouse umumnya tidak statis. Biaya perawatannya cukup tinggi.
- Data warehouse dapat menjadi ketinggalan dari data terbaru relatif cepat. Maka, akan ada resiko bahwa data yang akan dianalisis di data warehouse merupakan data yang tidak optimal.
Contoh aplikasi dari Data Warehouse
- Analisis kartu kredit
- Analisis kecurangan asuransi
- Analisis panggilan telepon
- Managemen logistik
Akhirnya, kelima post untuk eksplorasi mengenai data warehouse telah dirilis. Semoga dapat bermanfaat. Secara singkat ,dapat disimpulkan bahwa data warehouse akan dibutuhkan oleh perusahaan-perusahaan besar dengan banyak cabang yang membutuhkan kemampuan pembuatan laporan dan analisis data. Maka daripada itu dibutuhkan gudang data yang tidak hanya sekedar menyimpan data namun juga memiliki kemampuan untuk mengolah, menganalisis, bahkan memperbaiki ketidakkonsistenan data yang terjadi. Data warehouse sendiri sendiri memiliki kelebihan dan kerugian, maka perlu dipertimbangkan dengan baik apakah memang dibutuhkan untuk menggunakan data warehouse atau tidak.
Daftar Referensi :
http://en.wikipedia.org/wiki/data_warehouse, diakses tanggal 8 Juni 2009
http://download.oracle.com/docs/cd/B28359_01/server.111/b28313/concept.htm diakses tanggal 1 Juli 2009
http://www.cs.bris.ac.uk/maintain/OracleDocs/server.816/a76994/concept.htm diakses tanggal 1 Juli 2009
http://www.datawarehouse4u.info/Data warehouse.htm, diakses tanggal 8 Juni 2009
Silberschatz, Database System Concepts, Fourth Edition
Basis Data Terdistribusi (Distributed Database)
June 9, 2009
oleh Christian Hadiwinoto (13507081)
Semua bagian posting telah selesai ditulis. untuk membaca per bagiannya, gunakan pranala berikut:
- Bagian I: Pengantar Basis Data Terdistribusi
- Bagian II: Pemanfaatan Basis Data Terdistribusi dan Masalah Transparansi
- Bagian III: Perancangan Basis Data Terdistribusi
- Bagian IV: Pemrosesan Query Terdistribusi
- Bagian V: Multidatabase dan Arsitektur Client/Server
(Penutup: Contoh Sistem dengan Oracle)
Bagian I: Pengantar Basis Data Terdistribusi
(9 Juni 2009)
Pengantar: Dalam posting hari ini akan dibahas gambaran umum mengenai basis data terdistribusi (distributed database), khususnya untuk menjawab pertanyaan mendasar “Apa itu basis data terdistribusi?”
Basis data terdistribusi (distributed database) adalah suatu basis data yang berada di bawah kendali sistem manajemen basis data (DBMS) terpusat dengan peranti penyimpanan (storage devices) yang terpisah-pisah satu dari yang lainnya. Tempat penyimpanan ini dapat berada di satu lokasi yang secara fisik berdekatan (misal: dalam satu bangunan) atau terpisah oleh jarak yang jauh dan terhubung melalui jaringan internet. Penggunaan basis data terdistribusi dapat dilakukan di server internet, intranet atau ekstranet kantor, atau di jaringan perusahaan.
Untuk menjaga agar basis data yang terdistribusi tetap up-to-date, ada dua proses untuk menjaganya, yakni replikasi dan duplikasi. Dalam replikasi, digunakan suatu perangkat lunak untuk mencari — atau lebih tepatnya melacak — perubahan yang terjadi di satu basis data. Setelah perubahan dalam satu basis data teridentifikasi dan diketahui, baru kemudian dilakukan perubahan agar semua basis data sama satu dengan yang lainnya. Proses replikasi memakan waktu yang lama dan membebani komputer karena kompleksitas prosesnya. Sementara itu, proses duplikasi tidak sama dan tidak sekompleks replikasi. Dalam proses ini, satu basis data dijadikan master, kemudian diperbanyak menjadi sejumlah duplikat. Selama proses duplikasi berlangsung, perubahan hanya boleh dilakukan pada basis data master agar data lokal tidak tertimpa.
Pengguna (user) dari sebuah basis data terdistribusi dapat mengakses basis data melalui dua jenis aplikasi, yakni
- aplikasi lokal: aplikasi yang tidak memerlukan data dari tempat lain
- aplikasi global: aplikasi dengan kebutuhan akan data dari tempat lain
Dalam proses perancangan basis data terdistribusi, harus diperhatikan aspek transparansi, yaitu interaksi user terhadap basis data merupakan interaksi dengan satu sistem secara utuh. Transparansi harus terlihat dalam dua hal, yaitu
- Distribusi: para pengguna harus dapat berinteraksi dengan sistem secara keseluruhan sebagai satu sistem yang utuh. Kesatuan ini harus ada pada kinerja sistem dan metode pengaksesan.
- Perubahan (transaksi): Setiap transaksi (penambahan, penghapusan, atau peng-update-an) harus mempertahankan integritas antara basis data yang berbeda-beda dalam satu sistem. Setiap transaksi harus dibagi ke dalam sejumlah subtransaksi, yang tiap-tiap darinya memberikan pengaruh pada keseluruhan sistem basis data.

ilustrasi basis data terdistribusi
Bagian II: Pemanfaatan Basis Data Terdistribusi dan Masalah Transparansi
(24 Juni 2009)
Pengantar: Setelah mendapat gambaran mengenai basis data terdistribusi pada posting dua pekan yang lalu, pertanyaan yang mungkin timbul selanjutnya adalah “Untuk apa basis data terdistribusi diimplementasikan?” Posting kali ini akan diawali dengan bahasan mengenai hubungan antara basis data terdistribusi dengan distributed computing. Pembahasan dilanjutkan dengan kelebihan dan kekurangan basis data terdistribusi, juga masalah (issue) transparansi dalam pengelolaan basis data terdistribusi.
Dengan demikian, pemanfaatan basis data terdistribusi dapat memudahkan perolehan informasi dari berbagai lokasi yang berbeda, bahkan berjauhan, di samping meningkatkan kinerja sistem dengan beberapa komputer yang bekerja bersamaan.
Basis data terdistribusi pada dasarnya adalah bagian dari sistem komputer terdistribusi, atau disebut juga distributed computing. Distributed computing sendiri adalah sistem yang dapat membuat komputer-komputer yang berbeda dan bekerja secara bersamaan dapat saling bertukar informasi dalam satu kesatuan sistem. Dengan basis data terdistribusi, operasi basis data dapat dikendalikan dari satu mesin (komputer) dan dijalankan pada mesin-mesin yang lain.
Sistem komputer terdistribusi, tentunya juga dengan basis data terdistribusi, dapat membantu penyelesaian berbagai masalah, khususnya yang berkaitan dengan bisnis. Sistem komputer terdistribusi dapat mempercepat aplikasi dengan membagi operasi-operasi pada mesin yang berbeda. Selain itu, komputer-komputer yang berpartisipasi dalam sistem komputer terdistribusi boleh jadi saling berjauhan letaknya. Dengan demikian, pemanfaatan basis data terdistribusi dapat memudahkan perolehan informasi dari berbagai lokasi yang berbeda, bahkan berjauhan, di samping meningkatkan kinerja sistem dengan beberapa komputer yang bekerja bersamaan.
Kelebihan dan Kekurangan Basis Data Terdistribusi
Pemanfaatan basis data terdistribusi dapat memberikan manfaat bagi sistem yang mengimplementasikannya. Hal ini disebabkan oleh kelebihan-kelebihan yang dimilikinya, antara lain
- kinerja yang lebih baik karena data ditempatkan di tempat yang sesuai dengan kebutuhan dan komputer-komputer dalam sistem dapat bekerja secara paralel, sehingga pembebanan pada komputer (server) menjadi seimbang.
- alasan ekonomis, yaitu bahwa merancang sistem yang terdiri atas jaringan komputer-komputer kecil (sederhana) dibandingkan dengan mengimplementasikan komputer tunggal yang canggih.
- alasan modularitas, yaitu bahwa sistem-sistem yang bekerja dalam basis data terdistribusi dapat dimodifikasi, ditambah, atau dikurangi tanpa memengaruhi modul lain (sistem lain dalam basis data terdistribusi). Dengan pembagian lokasi data, jika terjadi masalah atau musibah pada sistem, tidak semua data terancam, melainkan hanya data pada tempat-tempat tertentu.
- alasan organisasi dan otonomi pada sistem-sistem yang berpartisipasi, misalnya pada suatu kantor perusahaan, terdapat beberapa departemen. Dengan basis data terdistribusi, data-data perusahaan dapat disebar ke tiap-tiap departemen yang bertanggung jawab atasnya.
Akan tetapi, di samping kelebihan-kelebihan yang dimilikinya, basis data terdistribusi juga memiliki kendala, antara lain
- masalah kompleksitas, yaitu bukan pekerjaan yang mudah untuk membuat basis data yang tersebar terlihat sebagai satu kesatuan. Administrator basis data mempunyai tugas ekstra untuk menjaga agar basis data yang tersebar di berbagai lokasi terlihat transparan. Di samping itu, pemeliharaan sistem-sistem yang berlainan lebih kompleks ketimbang pemeliharaan sistem besar yang utuh sebagai satu kesatuan. Tingginya kompleksitas juga dapat menyebabkan pembengkakan biaya.
- masalah desain, yaitu bahwa desain yang dibuat harus memperhatikan arsitektur komputer yang terdiri atas sistem-sistem yang terpisah, selain itu juga memperhatikan data yang difragmentasi (dipecah-pecah) ke dalam lokasi berlainan. Perubahan dari basis data terpusat menjadi terdistribusi juga menjadi masalah karena belum ada standar metodologi dalam konversi DBMS terpusat menjadi DBMS terdistribusi.
- keamanan data, yaitu bukan hanya satu sistem yang harus diberi proteksi keamanan data, melainkan juga fragmen-fragmennya yang tersebar di berbagai lokasi, juga jalur komunikasi antarsistem.
- kendala mempertahankan integritas karena dalam menjaga integritas sistem melalui jaringan juga dapat memakan resource yang besar dari jaringan.
Masalah-Masalah yang Harus Diperhatikan (Issues) dalam Basis Data Terdistribusi
Dalam aplikasi sistem manajemen basis data terdistribusi (DDBMS), ada beberapa masalah (issue), yang harus diperhatikan, antara lain:
- transparansi
- perancangan (desain)
- pemrosesan query
- manajemen transaksi
- arsitektur dan middleware
Issue Transparansi dalam Basis Data Terdistribusi
Dalam posting dua pekan yang lalu, telah dibahas bahwa distribusi dan transaksi data dalam basis data terdistribusi harus transparan. Secara lebih rinci, untuk memelihara transparansi dalam basis data terdistribusi, ketiga aspek transparansi berikut ini harus diperhatikan:
- Jaringan: keberadaan jaringan dalam implementasi basis data harus seolah-olah tidak ada dalam pandangan pengguna. Penggunaan bahasa query (query language) harus tidak terikat pada lokasi penyimpanan data. Selain itu, lokasi penyimpanan data tidak boleh disertakan pada penamaan data. Sebagai akibatnya, semua nama yang digunakan pada basis data harus unik di seluruh sistem. Selain itu, pencarian data dalam basis data terdistribusi harus dibuat efisien dan pemindahan lokasi data pada basis data harus dibuat mudah.
- Replikasi: data pada basis data terdistribusi mungkin memiliki replika pada lokasi yang berbeda. Pembuatan replika ini harus ada di bawah kendali sistem, bukan pengguna. Termasuk di dalam aspek ini modifikasi data, yaitu tiap-tiap replika harus selalu diperbaharui dan mekanisme kontrol konkurensi harus menangani replika berdasarkan konsistensi pembacaan.
- Fragmentasi: jika basis data terdistribusi bersifat terfragmentasi (secara detailnya akan dibahas pada posting selanjutnya), setiap query yang dimasukkan oleh pengguna harus ditangani sistem sedemikian sehingga mempengaruhi relasi-relasi yang terbagi dalam fragmen-fragmen. Sistem juga harus bisa menangani query sedemikian sehingga keseluruhan sistem dapat memperoleh hasil dari satu query dari lokasi yang berbeda-beda.
Bagian III: Perancangan Basis Data Terdistribusi
(7 Juli 2009)
Pengantar: Dalam posting bagian ini akan dibahas perancangan basis data
terdistribusi berikut masalah-masalah yang berkaitan dengannya.
Seperti halnya proses perancangan sistem lainnya, perancangan basis data terdistribusi juga memerlukan serangkaian proses analisis dan desain. Termasuk di dalam proses ini adalah analisis kebutuhan beserta proses-proses perancangan, yakni desain secara konseptual bersama dengan desain tampilan (view) informasi; desain distribusi yang melibatkan pengaturan pembagian data; kemudian desain fisik (lihat gambar).

bagan proses perancangan basis data terdistribusi
Fragmentasi
Dalam basis data terdistribusi, fragmentasi dilakukan pada relasi-relasi yang ada pada basis data. Fragmentasi membagi suatu relasi yang ada menjadi sejumlah fragmen atau pecahan relasi yang tetap mempertahankan keutuhan informasi semula. Kelebihan dari fragmentasi, yang menjadi alasan dilakukannya adalah dimungkinkannya pemrosesan data secara paralel dan penempatan tupel relasi, yang berisi sejumlah informasi, pada tempat yang tepat, yaitu yang paling membutuhkannya. Fragmentasi sendiri terbagi atas empat jenis, yaitu:
- primary horizontal: sebuah relasi R(A1, …, An) difragmentasi berdasarkan himpunan predikat-predikat relasi PR = {p1, …, pn}. Tiap-tiap predikat merupakan perbandingan yang digunakan dalam aljabar relasional, yang dapat melibatkan operator perbandingan =, ?, <, atau >.
- derived horizontal: pembuatan partisi suatu relasi R berdasarkan partisi yang dibuat pada relasi lain, misalkan S. Satu atau beberapa atribut di R mengacu kepada primary key pada S.
- vertical: fragmentasi ini dilakukan dengan memisah-misahkan atribut-atribut dari skema relasi R ke dalam skema-skema Ri. Setiap fragmen relasi harus memiliki primary key relasi asli.
- hybrid: fragmentasi yang mempunyai pola campuran dari ketiga relasi di atas
Ilustrasi Fragmentasi
Misalkan ada dua relasi sebagai berikut:
PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep) DEPT(NoDep, NamaDep, Lokasi)
Contoh fragmentasi untuk tiga jenis fragmentasi yang telah disebutkan di atas adalah sebagai berikut:
- dalam fragmentasi primary horizontal, dimisalkan ada himpunan predikat yang diakses oleh aplikasi yang berbeda. Satu aplikasi memperoleh informasi pegawai dengan posisi DBAdmin, sementara aplikasi lainnya memperoleh informasi pegawai dengan gaji lebih besar dari Rp 15 juta. Predikat sederhana dapat dinyatakan dalam himpunan sbb: . Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu
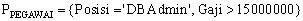 . Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut
. Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut
- m1 = Posisi = ‘DBAdmin’ ^ Gaji > 15000000
- m2 = Posisi ? ‘DBAdmin’ ^ Gaji > 15000000
- m3 = Posisi = ‘DBAdmin’ ^ Gaji = 15000000
- m4 = Posisi ? ‘DBAdmin’ ^ Gaji = 15000000
- dalam fragmentasi derived horizontal, misalkan DEPT dipartisi berdasarkan predikat Lokasi = ‘Bandung’, sehingga ada dua partisi
DEPT1 = sLokasi = ‘Bandung’(DEPT) DEPT2 = sLokasi ? ‘Bandung’(DEPT)
sementara, itu PEGAWAI dipartisi berdasarkan partisi DEPT sebagai berikut:
PEGAWAIi PEGAWAI left outer join DEPTi
- dalam fragmentasi vertical, relasi PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep) difragmentasi ke dalam fragmen relasi PEGAWAI1(NoPeg, NamaPeg, Gaji) dan PEGAWAI2(NoPeg, Posisi, NoDep).
Ketepatan Fragmentasi
Fragmentasi dikatakan tepat apabila memenuhi syarat-syarat berikut:
- kelengkapan: dekomposisi relasi R ke dalam fragmen-fragmen R1, …, Rn dikatakan lengkap jika setiap tupel R dapat ditemukan dalam fragmen Ri mana pun.
- rekonstruksi: jika relasi R terdekomposisi ke dalam fragmen-fragmen R1, …, Rn, terdapat operator relasional
 sedemikian sehingga
sedemikian sehingga  .
. - disjoint: jika sebuah relasi R dipartisi, sebuah tupel dalam R, jika ditemukan dalam fragmen Ri, tidak akan ditemukan dalam fragmen Rj dengan i ? j.
Alokasi
Dalam basis data terdistribusi, alokasi mengacu kepada distribusi data ke tempat yang optimal. Ada tiga aspek dalam memastikan alokasi menjadi optimal, antara lain
- biaya minimal, yang mencakup aspek komunikasi, penyimpanan, dan pemrosesan (pembacaan dan update); biaya mengacu pada waktu dan biaya jaringan
- kinerja, yang mencakup waktu respons dan throughput
- konstrain pemrosesan dan penyimpanan per situs (tempat menyimpan data)
Alokasi – Kebutuhan Informasi
Untuk dapat mengalokasikan basis data terdistribusi secara optimal, dibutuhkan informasi-informasi tentang sistem sebagai berikut:
- informasi basis data
- skema konseptual basis data dan jumlah situs tersedia
- jumlah, ukuran, dan selektivitas fragmen per relasi global
- informasi aplikasi
- jumlah query aplikasi
- rata-rata jumlah akses baca dariquery ke dalam sebuah fragmen
- rata-rata jumlah akses update dari query ke dalam sebuah fragmen
- matriks yang menunjukkan query mana yang meng-update dan/atau membaca fragmen tertentu
- situs asal tiap-tiap query dijalankan
- informasi situs
- unit cost penyimpanan data dalam satu situs
- unit cost pemrosesan data dalam satu situs
- informasi jaringan
- komunikasi antara dua situs, mencakup antara lain bandwidth dan tunda (latency)
Replikasi
Sistem basis data terdistribusi dapat menyimpan duplikat dari data yang sama dalam site yang berbeda agar perolehan informasi yang semakin cepat dan toleransi kesalahan. Proses ini disebut replikasi. Replikasi pada relasi bersifat redundan pada dua atau lebih situs.
Replikasi pada relasi disebut replikasi penuh bila relasi tersebut disimpan pada semua situs. Basis data disebut redundan penuh jika tiap-tiap site mengandung duplikat dari keseluruhan basis data.
Replikasi dilakukan karena memiliki kelebihan sebagai berikut:
- jika situs asli yang menyimpan relasi R mengalami kegagalan, relasi R tetap dapat diakses melalui replikanya
- query pada relasi R dapat berjalan secara paralel di simpul (situs) yang berbeda
- lebih sedikit transfer data, yaitu tidak perlu lagi mengambil data suatu relasi melalui jaringan karena sudah ada replika dalam situs lokal.
Namun, proses replikasi juga memiliki kelemahan, antara lain
- proses update yang lebih rumit karena setiap replika relasi R harus di-update.
- kendali atas konkurensi yang lebih rumit karena update terhadap replika secara konkuren dapat menyebabkan basis data menjadi tidak konsisten sehingga diperlukan mekanisme khusus dalam penanganan konkurensi.
Sementara itu, dalam melakukan replikasi, ada dua strategi, yaitu
- sinkron: sebelum seluruh proses transaksi update dinyatakan selesai, data yang telah dimodifikasi disinkronkan ke setiap duplikatnya; proses ini harus menunggu hingga data di tempat penyimpanan duplikat selesai ditulis sebelum dilakukan perubahan lainnya sehingga menjadi lebih kompleks
- asinkron: copy data diperbaharui secara periodik berdasarkan data utama yang diperbaharui; proses penulisan data selesai tanpa perlu menunggu penulisan data di tempat penyimpanan duplikat selesai; proses ini memang meningkatkan kinerja sistem namun risikonya, inkonsistensi data bisa terjadi.
Bagian IV: Pemrosesan Query Terdistribusi
(21 Juli 2009)
Pengantar: Dalam posting bagian ini akan dibahas masalah (issue) lainnya dalam basis data terdistribusi, yaitu pemrosesan query terdistirbusi, berikut pertimbangan dan contoh kasus dalam pembuatan query.
Pemrosesan query pada basis data terdistribusi berbeda dari pemrosesan query pada basis data terpusat. Query–query pada relasi global perlu disesuaikan agar dapat menganani relasi-relasi dalam fragmen. Pembuatan query pada perancangan basis data terdistribusi dapat diilustrasikan dengan bagan di bawah ini.

Bagan pembuatan query terdistribusi
Pada basis data terpusat, evaluasi query harus memperhatikan faktor pengaksesan storage (disk), yakni jumlah blok pada hard disk yang dibaca/tulis. Sementara itu, dalam pemrosesan query pada basis data terdistribusi, diperlukan pula pertimbangan dari sisi
- transmisi data melalui jaringan
- peningkatan kinerja yang potensial akibat pemrosesan query secara paralel
Dalam membuat query pada basis data terdistribusi, perlu diperhatikan hal-hal sebagai berikut:
- penyesuaian dari query relasi global ke query terhadap fragmen, yaitu bahwa ekspresi relasi global dalam query harus disesuaikan menjadi ekspresi relasi fragmen; relasi global harus dapat direkonstruksi (dibuat terlihat global) dari fragmen-fragmennya
- penyederhanaan ekspresi aljabar relasional, juga deteksi dan penghilangan redundant
- pemilihan strategi join yang optimal (khususnya pada program yang melakukan “semi-join“)
- pemilihan rencana pemrosesan query yang optimal
Sebagai contoh, jika dimisalkan terdapat relasi global PARTS(PartNo, OrderNo, Price) yang dipartisi menjadi
- PARTS1:= σ0≤PartNo≤300(PARTS)
- PARTS2:= σ301≤PartNo≤500(PARTS)
- PARTS3:= σ501≤PartNo≤999(PARTS)
Query Q = σ25≤PartNo≤350(PARTS) pada relasi global dapat diubah menjadi bentuk query fragmen berikut:
- mengganti relasi global menjadi definisi fragmen-fragmennya:
Q1 = σ25≤PartNo≤350(PARTS1 ∪ PARTS2 ∪ PARTS3) - melakukan pushdown pada tiap-tiap fragmen:
Q2 = σ25≤PartNo≤350(PARTS1) ∪ σ25≤PartNo≤350(PARTS2) ∪ σ25≤PartNo≤350(PARTS3)
Pemrosesan Paralel pada Query Fragmen
- Jika dimisalkan sebuah relasi R difragmentasi secara horizontal (seperti contoh sebelumnya) menjadi R1 ∪ … ∪ Rn, aljabar relasional seleksi dan proyeksi menjadi
σF(R) ≡ (σF(R1)) ∪ … ∪ (σF(Rn))
πattr(R) ≡ (πattr(R1)) ∪ … ∪ (πattr(Rn)) - Fungsi-fungsi agregat (query Q(R) diasumsikan menghasilkan relasi satu kolom)
- min(Q(R)) ≡ min(Q(R1), …, Q(Rn))
- max(Q(R)) ≡ max(Q(R1), …, Q(Rn))
- sum(Q(R)) ≡ sum(Q(R1)) + … + sum(Q(Rn))
- Operasi R join S
Jika dimisalkan relasi S difragmentasi berdasarkan fragmentasi relasi R, sedemikian sehingga R = R1 ∪ R2 dan S = S1 ∪ S2, setiap fragmen dari R hanya perlu digabungkan (di-join) dengan fragmen dari S yang bersesuaian dengannya.
Pemrosesan Join Query
Jika terdapat relasi-relasi pada tempat (situs) yang terpisah, misalnya relasi R di situs A1, S di A2, dan T di A3, query R join S join T yang dilakukan pada situs Ai, harus ditampilkan hasilnya pada situs Ai. Strategi pemrosesan query yang mungkin adalah sebagai berikut:
- Meng-copy salinan semua relasi R, S, dan T ke situs Ai, kemudian melakukan join secara lokal di Ai
- Melakukan join secara bertahap, sbb:
- menyalin R ke A2 dan menghasilkan temp1 = R join S
- temp1 disalin ke A3 dan menghasilkan temp2 = temp1 join T
- temp2 sebagai hasil akhir dipindahkan ke Ai
Strategi join di atas dapat dipilih dengan mempertimbangkan faktor-faktor berikut:
- jumlah data yang ditransfer (salin)
- biaya (resource) yang diperlukan untuk transfer data antarsitus
- kecepatan pemrosesan di tiap situs
Operasi join dapat pula dioptimalkan dengan menggunakan strategi semijoin. R semijoin S ≡ πattr(R) (R join S). Jika dimisalkan relasi R disimpan di A1 dan S di A2, kemudian dilakukan operasi R join S pada A1), strategi semijoin dapat diilustrasikan sebagai berikut:
- lakukan proyeksi di A1 hanya dengan atribut yang dimiliki R dan S; temp1 := πattr(R) ∩ attr(s)(R)
- hasil temp1 disalin ke A2 dan di-join dengan S; temp2 := S join temp1; perhatikan bahwa temp2 adalah juga S semijoin R
- temp2 disalin ke A1 dan dilakukan operasi R join temp2
Strategi semijoin di atas dapat meningkatkan efisiensi operasi join karena data yang dipertukarkan melalui jaringan menjadi lebih kecil. Untuk membuat join lebih efisien, dapat diimplementasikan program (semi-)join yang memiliki pemroses query (query processor) untuk membuat partisi dari sederetan join seperti R1 join R2 join … Rn menjadi kumpulan semijoin yang lebih efisien. Pemilihan semijoin dilakukan dengan mempertimbangkan perpindahan data (resource dan waktu) beserta konstrain yang terkait, misalnya waktu respon maksimum dari query.
Bagian V: Multidatabase dan Arsitektur Client/Server (Penutup: Contoh Sistem dengan Oracle)
(30 Juli 2009)
Pengantar: Posting terakhir ini akan membahas aspek multidatabase, termasuk proses pembuatannya dengan proses integrasi basis data, juga aplikasi pendukung basis data terdistribusi, yaitu arsitektur klien/server. Sebagai penutup akan dibahas pula contoh sistem basis data terdistribusi menggunakan Oracle.
Multidatabase
Suatu sistem basis data terdistribusi adakalanya dibentuk dari beberapa basis data yang berlainan. Sistem seperti ini disebut multidatabase, yang pembentukannya dilakukan dengan integrasi basis data. Dalam melakukan integrasi ini, boleh jadi ada ketidakseragaman antara basis data-basis data yang membentuknya dan mengakibatkan konflik, baik konflik skema (akibat ketidakseragaman skema relasi) maupun konflik data (akibat ketidakakuratan isi, misalnya presisi, besaran dan satuan, juga data yang tidak tepat atau sudah tidak berlaku [obsolete]). Oleh karena itu, perlu diperhatikan metode penyelesaian konflik yang terjadi.
Penyelesaian konflik saat integrasi basis data harus memerlukan analisis yang mendalam akan komponen basis data dan tidak dapat diotomatisasi. Adapun sebelum dilakukan integrasi, komponen basis data harus dipersiapkan terlebih dahulu, khususnya untuk penanganan konflik. Proses ini disebut restrukturisasi. Ilustrasi restrukturisasi dan integrasi basis data dapat dilihat pada bagan berikut:

Bagan Proses Restrukturisasi dan Integrasi Basis Data
Penyelesaian konflik pada restrukturisasi (untuk integrasi) basis data dapat dilakukan dengan menggunakan view, yaitu relasi/tabel bentukan virtual yang bukan bagian dari skema relasi itu sendiri, tetapi dapat diperlakukan sebagaimana relasi melalui query dan view lain. View hanya perlu disimpan definisinya di kamus data tanpa perlu relasinya.
Berikut ini adalah konflik yang dapat terjadi pada proses integrasi basis data berikut contoh penanganannya:
- konflik antartabel
- antara dua tabel
- nama tabel (homonim/sinonim), dapat diselesaikan dengan definisi view sendiri
- struktur tabel, seperti jumlah atribut berbeda di dua tabel yang informasinya sama, dapat diselesaikan dengan membuang atribut yang keberadaannya tidak di semua relasi atau menambahkan atribut yang kurang pada relasi yang kekurangan atribut (bila perlu dengan nilai default-nya)
- integrity constraint, misalnya pada dua situs terdapat tabel yang sama tetapi isi atribut primary key-nya berbeda, dapat diselesaikan dengan memberikan primary key tambahan yang berisi informasi situs relasi itu disimpan
- antara banyak tabel, misalnya pada dua komponen basis data jumlah relasinya tidak sama tetapi informasinya sama, dapat diselesaikan dengan penggabungan relasi dengan view
- antara dua tabel
- konflik antaratribut
- antara dua atribut
- nama atribut (homonim/sinonim), dapat diselesaikan dengan penggantian nama (rename) atribut di view
- integrity constraint, misal tipe data, dapat diselesaikan dengan fungsi-fungsi konversi, seperti to_char(int) atau to_int(char), pada view
- antara banyak atribut, misalnya dalam penyimpanan informasi nama orang dalam tabel yang satu digunakan dua atribut (kolom): nama depan dan nama belakang, sementara pada tabel yang lain digunakan satu atribut nama lengkap; konflik ini dapat diselesaikan dengan penggabungan string atau pemisahan string dengan fungsi substring
- antara dua atribut
- konflik tabel-atribut, dapat merupakan kombinasi dari permasalahan di atas
Arsitektur Klien/Server
Basis data terdistribusi adalah bagian dari sistem komputer terdistribusi. Arsitektur klien/server adalah model arsitektur perangkat lunak yang umum digunakan dalam sistem ini. Sistem dipisahkan antara klien dan server; kerjanya adalah sebagai berikut: sistem klien melakukan permintaan dan sistem server memproses permintaan tersebut. Fungsionalitas dalam arsitektur klien/server dapat dibagi menjadi tiga, yaitu:
- fungsi presentasi, mencakup antarmuka seperti peranti input dan form
- fungsi aplikasi, spesifik terhadap aplikasi yang digunakan
- fungsi manajemen data, yang mengelola akses data dalam arsip atau basis data
Bagan ilustrasi arsitektur klien/server adalah sebagai berikut:

Fungsionalitas basis data pada arsitektur klien/server dibagi menjadi dua:
- front-end, berhubungan dengan pengguna dan mencakup penanganan masukan, antarmuka pengguna, dan pembuatan report.
- back-end, berhubungan dengan akses data dan penanganan query, kontrol concurrency, dan recovery
Untuk menghubungkan keduanya, digunakan SQL atau application program interface, dapat berupa ODBC atau JDBC.
Ada dua jenis sistem server yang umum digunakan, yaitu server transaksi dan server data. Perbedaannya adalah
- pada server transaksi, klien hanya perlu mengirimkan permintaan melalui application program interface, seperti ODBC dan JDBC; selanjutnya serangkaian prosedur (transaksi) yang berhubungan dengan pemrosesan query dijalankan di server
- pada server data, seluruh fungsionalitas back-end dilakukan di klien, termasuk pemrosesan query data; server mengirimkan seluruh data yang diminta ke klien, bukan hasil query
Contoh Sistem: Sistem Basis Data Terdistribusi dengan Oracle
Basis data terdistribusi dapat diimplementasikan dengan berbasiskan sistem Oracle. Dalam implementasinya, sistem basis data terdistribusi dengan Oracle dapat digolongkan menjadi dua:
- sistem basis data terdistribusi homogen: seluruh sistem menggunakan basis data Oracle yang bertempat di satu atau beberapa mesin; Oracle yang digunakan boleh jadi berbeda versi, tetapi aplikasi harus dapat memahami perbedaan fungsionalitas yang ada di setiap simpul (basis data) sistem

Ilustrasi Sistem Basis Data Terdistribusi Homogen
- sistem basis data terdistribusi heterogen: sedikitnya satu sistem bagian tidak menggunakan basis data Oracle; agar dapat saling berkomunikasi, perbedaan ini dapat dijembatani dengan menerapkan salah satu dari berikut:
- Oracle Transparent Gateway yang menggunakan layanan heterogen pada server Oracle (Oracle Heterogenous Services) dan agen yang spesifik terhadap sistem pada sistem non-Oracle
- konektivitas generik (generic connectivity), yang dapat diimplementasikan di server Oracle dan berupa Heterogenous Services ODBC agent atau Heterogenous OLE DB agent; dengan mengimplementasikannya, tidak diperlukan lagi aplikasi agen yang spesifik-sistem, tetapi sumber data harus kompatibel dengan ODBC atau OLE DB agar dapat diakses

Ilustrasi Sistem Basis Data Terdistribusi Heterogen
–= Tamat =–
Daftar Referensi
- Albion Research. 2009. “Synchronous Replication (Definition).” Dalam Risky Thinking [online]. URL: http://www.riskythinking.com/glossary/synchronous_replication.php [akses: 7 Juli 2009 pukul 13.12 WIB].
- Anwar, Gunadi, dkk. 2006. Jaringan Klien Server [makalah-ebook]. URL: http://www.wimpermana.web.ugm.ac.id/budi_s/wp-content/client_server.pdf [akses: 28 Juli 2009 pukul 20.35 WIB].
- Geier, Martin. 1999. “Why Use Distributed Computing.” Dalam CORBA FAQ [online]. URL: http://www4.informatik.uni-erlangen.de/~geier/corba-faq/why-distrib-computing.html [akses: 23 Juni 2009 pukul 11.26 WIB].
- Gertz, Michael. 2003. “Distributed Database Systems.” Dalam ECS 165B Database Systems, Spring 2003 [ebook]. URL: http://teknik.unitomo.ac.id/elearning/e_learning/database%20terdistribusi/additional%20material.pdf [akses: 18 Juni 2009 pukul 11.55 WIB].
- Oracle Corporation. 2003. “29 – Distributed Database Concept.” Dalam Oracle Database Administrator’s Guide 10g Release 1 (10.1) [online]. URL: http://www.sc.ehu.es/siwebso/KZCC/Oracle_10g_Documentacion/server.101/b10739/ds_concepts.htm [akses: 23 Juni 2009 pukul 11.24 WIB].
- Wikipedia. 2009. “Distributed Database.” Dalam Wikipedia, the free encyclopedia [online]. URL: http://en.wikipedia.org/wiki/Distributed_database [akses: 2 Juni 2009 pukul 19.39 WIB].
- __________. 2009. “Replication (Computer Science).” Dalam Wikipedia, the free encyclopedia [online]. URL: http://en.wikipedia.org/wiki/Replication_(computer_science) [akses: 7 Juli 2009 pukul 13.16 WIB].
Bidang Kuliah di Teknik Informatika ITB yang Terkait
(diurutkan berdasarkan alfabet)
- EL2010 Organisasi dan Arsitektur Komputer
- IF2034 Basis Data
- IF3035 Sistem Basis Data
- IF3097 Jaringan Komputer
- IF3056 Sistem Terdistribusi
- IF4030 Sistem Basis Data Terdistribusi
Hello Basdat !
May 13, 2009
Selamat datang calon warga laboratorium basis data… Kami dengan senang hati menerima seluruh calon warga basis data sehingga menjadi asisten yang tangguh, loyal, setia, baik hati, dan pintar menabung… sekali lagi selamat datang !
